What is Data Masking?
Data masking is a technique used to protect sensitive data by replacing it with fictional but realistic data. This ensures that the data remains usable for testing, development, and analytics while safeguarding the original information from unauthorized access. It is commonly used to comply with data privacy regulations and to mitigate the risk of data breaches. By obfuscating data, organizations can maintain data integrity without exposing actual sensitive information.
Keep reading to learn:
- When do you need to mask data?
- How does it help security teams?
- What are the common techniques?
- Which strategies should I consider?
- Why is data masking complex?
- A practical framework for data masking
When is Data Masking Important?
- Development and Testing Environments:
Using real data in development and testing environments can expose sensitive information. Data masking ensures that developers and testers can work with realistic data without risking data spillage. - Data Analytics and Reporting:
Analysts often need access to large datasets that may contain personal or confidential information. Data masking allows them to generate insights and reports without compromising sensitive data. - Third-Party Sharing:
Organizations often share data with third-party vendors for various purposes. Masking data before sharing it with external parties prevents unauthorized access to sensitive information. - Regulatory Compliance:
Many industries are subject to stringent data protection regulations. Data masking helps organizations comply with regulations such as GDPR, HIPAA, and PCI DSS by protecting sensitive data. - Risk Mitigation:
Reduce the potential impact of a security breach by rendering sensitive information less valuable to unauthorized access, safeguarding against unauthorized use or exposure of critical data.
How does masking help security teams?

By substituting real data with masked data, it ensures that even if unauthorized access occurs, the data is of no practical use to the attacker. This method is particularly effective in non-production environments such as development, testing, and analytics, where the use of live data is unnecessary and risky.

Most privacy regulations require organizations to implement appropriate technical measures to ensure security of PII data. Data masking fulfills this requirement by anonymizing personal data, thus protecting individuals’ privacy.

By masking sensitive data before it leaves its country of origin, organizations can ensure compliance with laws that mandate data to remain within specific geographic boundaries. This reduces the risk of violating data sovereignty regulations while still enabling global data processing and analysis.
Masking techniques
The below table outlines popular masking techniques with examples:

Masking strategies
Static Data Masking
Involves masking data at rest, typically in a non-production environment. The data is masked and then stored, ensuring that sensitive information is never exposed.
Dynamic Data Masking
Masks data in real-time as it is accessed by applications or users, without altering the underlying database. This allows for secure access to data without modifying the original dataset.
On-the-Fly Data Masking
Similar to dynamic masking but specifically for data in transit. It masks data as it is moved from one environment to another, ensuring that sensitive information is protected during transfer.
Why is Data Masking so Complex?

A Practical Framework for Data Masking

Masking strategy applied based on the type of asset
- Dynamic data masking for production databases and any replicas
- On the fly masking for any ETL jobs
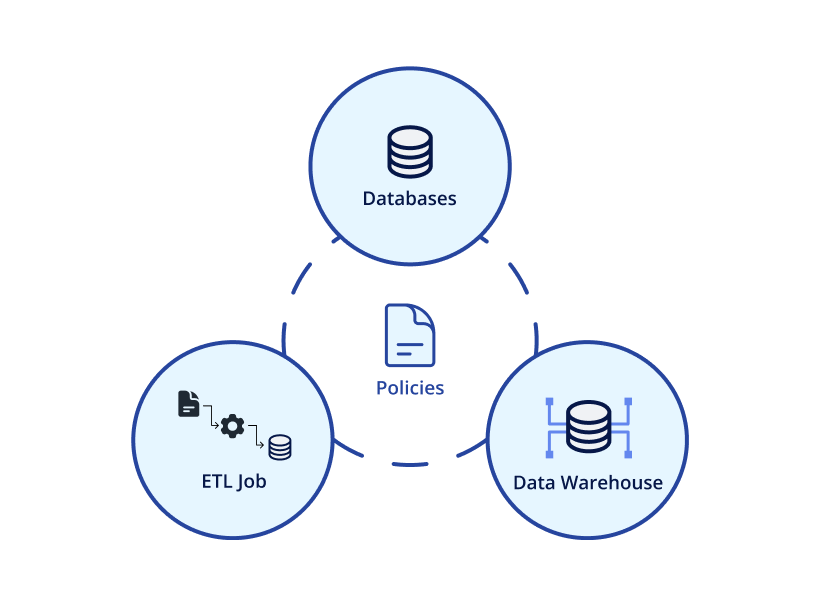
Centralized masking policies across the data stack
- Use an external authorization service to implement and manage policies
- Decouple policy management from database administration
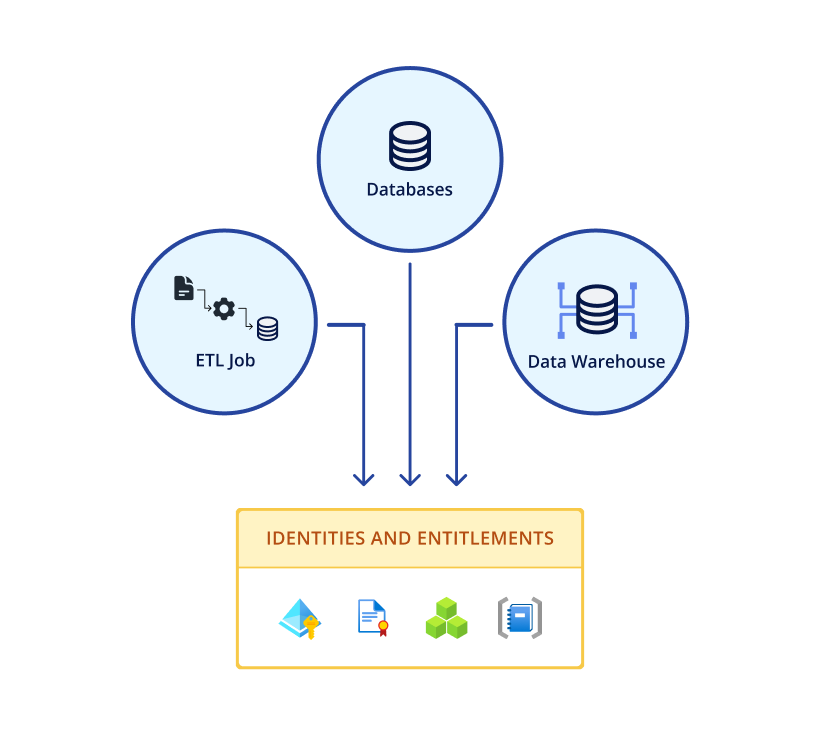
Specify policies in terms of federated identities
- Policies are invoked based on user’s IAM entitlements
- Ensure queries from service accounts are annotated with user identity

Ensure policies follow the data
- Specify policies on the type of data (eg PII) as opposed to specific fields
- Implement discovery & classification to keep the data labeling updated
Benefits of this approach
-
Eliminate the need to manage roles and permissions within databases
-
Provide flexibility in updating and managing policies
-
Keep policies in sync with IAM and compliance posture
-
Ensure that policies are always enforced on sensitive data
-
Provide one-click reporting for audit and assurance
-
Eliminate the need to maintain multiple copies of source data