
“Who accessed your data?” It’s an easy question to ask, but a really difficult question to answer. Database logs are really anemic, so we often pretend that application logs are sufficient. App properties are well integrated with Single-Sign On (SSO) providers, and offer a great experience for users. But how do we get this identity context in database logs? How do we answer the question, “Who accessed your data?” without blindly assuming the question was “Who accessed your application?” Let’s look at the existing state of database security and identity validation, look at why application SSO use is so successful, and look for methodologies and tools that can add identity validation to data use both from applications and non-app tools. You can secure your data, and confidently answer “Who accessed your data?”
The Problem: Who Accessed Your Data?
Who accessed your data? This question may make you a little bit uneasy. It was really easy to ask, but it’s incredibly hard to answer. You may feel like you’re under the microscope or even worse in the interrogation chair.
We may get asked this question when we’re in the middle of an audit trying to justify our behavior over the last year. Or we may get asked this question as we clean up from a data breach. Or we may ask this question of our software when data integrity is compromised. In most cases, we’re answering this data in a very reactionary way.
Database Logs
How do we answer the question, “Who accessed your data?” We could head to the database logs to see if we can answer the question from there. But often, there are no logs. This is not an uncommon configuration for us to just disable the database logs.
But why do we often turn off the database logs?
Latency: Generally, the slowest part of our application is data access: connecting to the database and retrieving data. And the slowest part of the database retrieving data is reading data from disk. When we write logs, we’re increasing the latency of our application by doing two disk operations. Therefore, we may choose to disable logging for performance reasons.
Storage: We may also choose to disable logs for storage reasons. The database server’s job is to store critical business data. In time, we may be storing a lot of it, and the disk size we chose so long ago may now seem too optimistic. How do we get more space on the drive? We do so by deleting the things we don’t need … like the database logs. If we don’t disable the logs completely, we may choose to truncate them to something miniscule like one day or one hour.
Application Logs
So back to the question, “Who accessed our data?” The database logs usually can’t tell us. They probably don’t exist, and if they do, they’re probably too anemic to gain valuable insight.
So, let’s look at application logs. .Anything that used our database probably came through our application, and we have great logging around application use. We probably have very pretty dashboards that show us authenticated user activity, page requests, response HTTP status codes, and the time it took to fulfil the request. Surely, we can present these logs to answer the question,“Who accessed our data?”
But are application logs sufficient to answer the question? Unfortunately, not really. We can enumerate many scenarios where connections are made to the database that don’t go through the application:
- An SRE jumps into a customer account to quickly fix some data error and get the customer back in gear.
- A DBA logs into the database to tune an index or rewrite a slow query.
- A deployment tool runs database migrations as part deploying the next version of the software.
- A bulk data extract tool can help onboard new customers or help customers who are leaving.
Are these connections going through the application? They’re probably not. They’re probably accessing the database directly via database administration tools.
We can probably enumerate another half-dozen scenarios where normal data access is not done through our application. And these are just the legitimate use-cases. If we’re looking for unwanted activity, it most likely didn’t come through the application either.
Using the application logs to answer the question about database access is a convenient lie. It was a helpful lie. And the lie got us off the hot seat. But it is a lie none-the-less. Data access doesn’t just happen through the application.
Enable the Database Logs
How do we answer the question, “Who accessed our data?” We’ve established that database logs probably don’t exist. We’ve established that pretending application logs answer the question is really a lie. Now what? Let’s turn on the database logs.
If we head to the Postgres documentation, we can see that by default the logs are disabled – likely for all the reasons we enumerated previously. Let’s change the log level from none to all:
postgres -c log_statement=all -c logging_collector=onWith logging turned on, let’s restart the database, use the application and terminal tools, and take a look at what we see.
2021-02-21 15:35:07 CET [3492-349] postgres@prod LOG: execute <unnamed>: SELECT id FROM public.task WHERE id = 7;
2021-02-21 15:35:07 CET [3492-350] postgres@prod LOG: duration: 11.069 ms
2021-02-21 15:35:08 CET [3494-223] postgres@prod LOG: duration: 0.030 ms
2021-02-21 15:35:08 CET [3494-224] postgres@prod LOG: duration: 0.081 msWe can see the queries run, we can see the date & time of the queries, we can see the time taken, but we can’t see who ran the query. If we log user information, we may only see the service account the application uses.
Even queries run by non-app tools probably still use the same service account. I bet the DBA or SRE user just popped open the web app, lifted the credentials from the configuration file, and logged in.
It’s far too difficult to create individual users in the database, keep these users in sync as employees join and leave — and so we don’t. Instead, we all use the same service account.
Who accessed the data? These logs don’t help us answer that question at all. Everything about the system is unable to answer this question.
Logs in Review
We’re still no closer to answering the question, “Who accessed the data?” The database logs are probably turned off for performance reasons, either to avoid the latency of additional disk access or to conserve precious storage resources. And even if we turned on the logs, all the access is using a single service account – both access from our microservices and access from non-app uses like DBA and SRE and DevOps tools. Database logs don’t include user identity information.
SSO with Apps
How do web apps solve the identity question? Let’s look at how applications use Single Sign On (SSO) to harvest and leverage identity context. The user experience and data flows with SSO are elegantly simple: the app, the identity provider (IdP), and the user all benefit from a really smooth experience.
The SSO workflow is great:
- The user launches the web app
- The user clicks login
- The browser redirects to the Identity Provider (IdP) login page
- The user logs into this trusted resource
- The browser redirects back to the application
- The user gets stuff done
The application, the identity provider, and the user all have a great experience here.
The identity provider safely stores user credentials in one place. The identity provider pesents a rich user context including a verified identity and group memberships. The application accepts this token and can make authorization decisions about the user based on their group memberships or other claims, but the web service doesn’t need to store credentials or verify the user’s email. If the user is already logged into the shared SSO identity provider, they may just get redirected straight back to the website without having to login again. This is a great user experience.
As we look at that mechanism inside of SSO, we have an elegant mechanism where the application, the identity provider, and the user worked together to create this elegant solution. If we look at the logs from our microservice, we can see the user’s identity, group memberships, the request URL, the response status code, the request duration, the date & time, and connection details like the source IP.
Why can’t we do SSO with data? It’s a solved problem with applications. Can we do this with our database?
SSO for Data
Single Sign On (SSO) is a great solution for applications. We get request and response details, connection details, and identity context. Why can’t we do this for data?
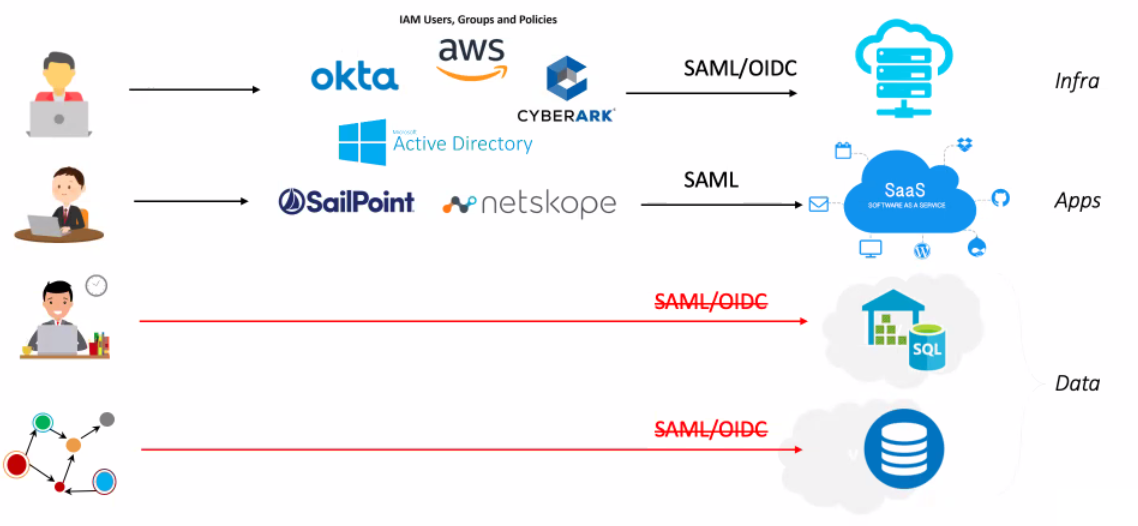
For web apps, we can easily forward off to an Identity Provider (IdP). With cloud resources we can authenticate with OIDC or SAML. But with on-prem and cloud data resources, we are back in the stone age with just a username and password. No SSO for data.
The Ideal Solution
What is the ideal solution? How can we best answer the question, “Who accessed the data?” Let’s learn from the SSO solutions with applications, and design the ideal logging solution that will give us identity context.
Let’s enumerate our ideal logging solution to answer this question:
- SSO Username
- SSO Group
- SQL query
- Result rows count
- Client connection details
- Date & time
This is what we want: the SQL query, the response details, the date & time, connection details, and user identity. Looking through this list, it looks very familiar. This is exactly the data we get with SSO-enabled applications. We get the authenticated user & groups, we get the request URL, the response status code, the number of bytes served, the user’s source IP, and the date & time of the query.
If we had this detail in our data logs, we could definitely and confidently answer the question, Who accessed our data? How do we get this level of detail for our data stores? Let’s add Cyral.
Adding Cyral
Cyral is a federated access control system. We can use consolidated policies and monitoring. And Cyral provides real time attack response. In short, Cyral solves the challenge and brings SSO to the data mesh.
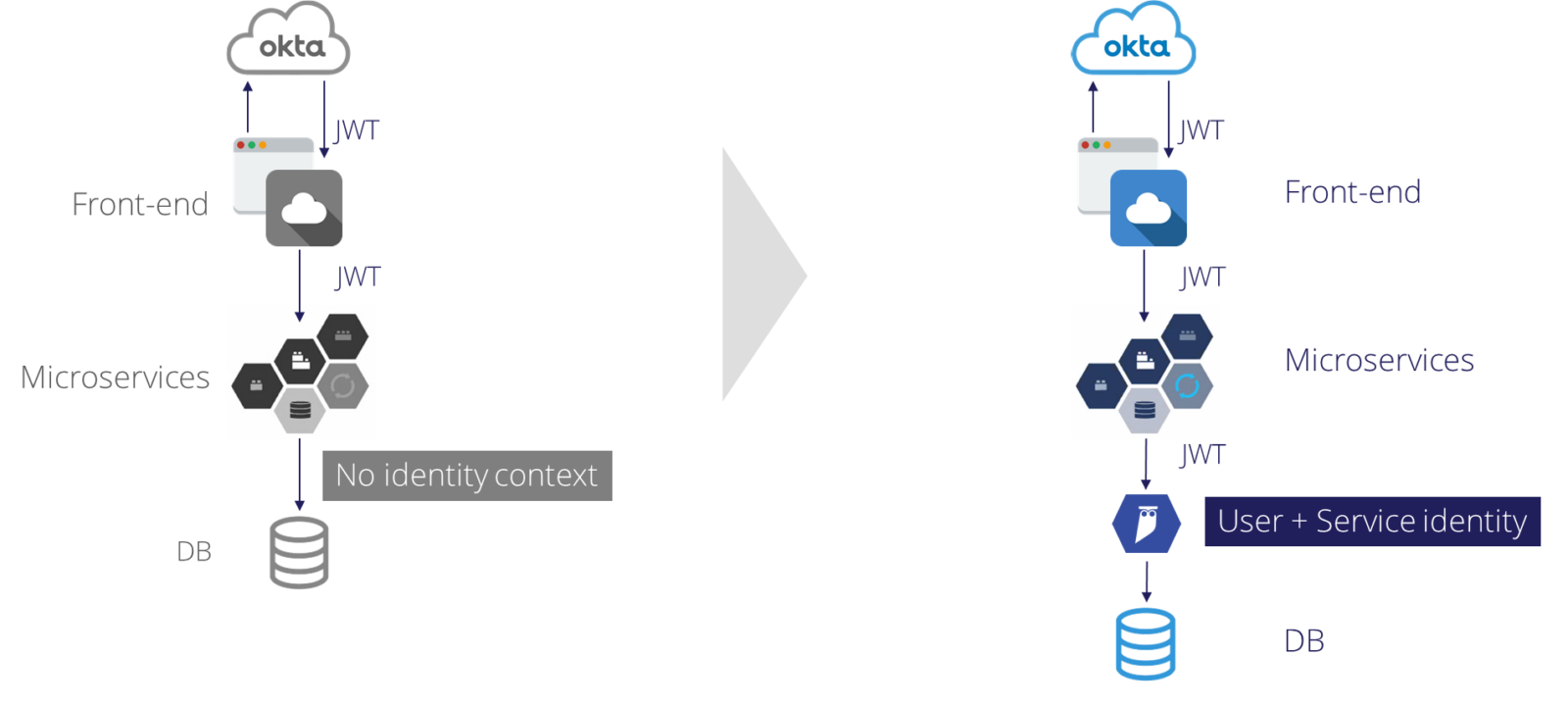
In the above diagram, we have the scenario before Cyral on the left. On the right, we have added Cyral to power identity context logging.
On the left, the front-end authenticates to the SSO provider, and retrieves a JWT with all the SSO groups and other claims. The application can pass this authentication token among the microservices to validate the user’s identity and make authorization decisions. However, as soon as a microservice reaches out into data, it flips to a shared service account, and that identity context is lost.
On the right, we’ve added Cyral. We use the same SSO authentication mechanism, retrieve the same JWT, and pass this authentication token through the microservices. Then we do something novel: we also pass this authentication token to the Cyral sidecar proxy. Cyral captures both the query request and response details as well as the user identity details. Cyral proxies the query to the data store, and the results are returned to the application. With Cyral, we can preserve the user identity through the data tier.
Now this is great for access inside of the application. We also noted that many data access use-cases don’t flow through the application: SREs, DBAs, and others connect straight to the data store. Let’s also look at data access through terminal or other specialty connections.
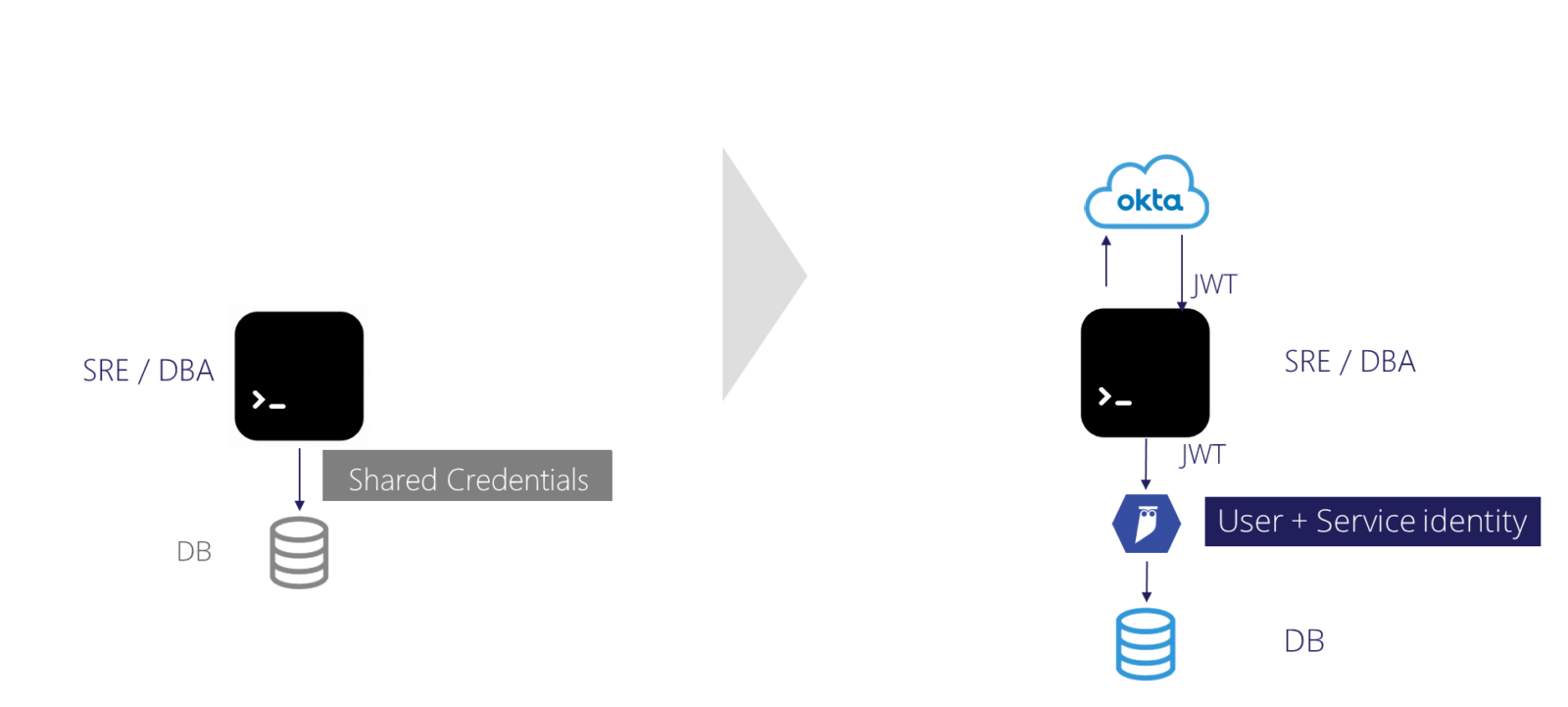
On the left in the above diagram, we have the traditional configuration. On the right we’ve added Cyral.
On the left, a user connects directly to the database. They’re probably using the shared service account. User identity is lost.
On the right, the user logs into their SSO provider of choice through the Cyral portal. From there, they get a token that authenticates them to the Cyral sidecar. Cyral captures the query request and response details as well as the user identity. Cyral then proxies the query to the data store.
For both application and non-application data access, Cyral captures the user identity in the midst of data access.
With Cyral, we can use various federated access controls: Okta Azure Active Directory, G-Suite, and more. We can connect to various data stores including MariaDB, MongoDB, SQL Server, and others. Cyral can send logs to your SIEM of choice: ELK, Splunk, DataDog, and more.
A Sample Application
Let’s take a tour through a Cyral-enabled setup. In this project we’ll illustrate:
- A Postgres database protected by a Cyral sidecar
- Okta as our SSO provider
- and logging details into Splunk.
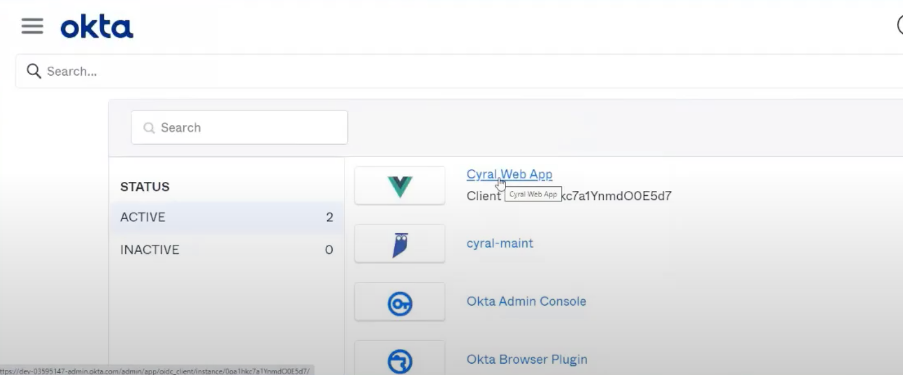
In Okta, we have two applications: One application is for our microservices. In this case, we validate users are part of the Accounting group. The other application is for non-app use, and we’ll validate users are part of the SRE group.
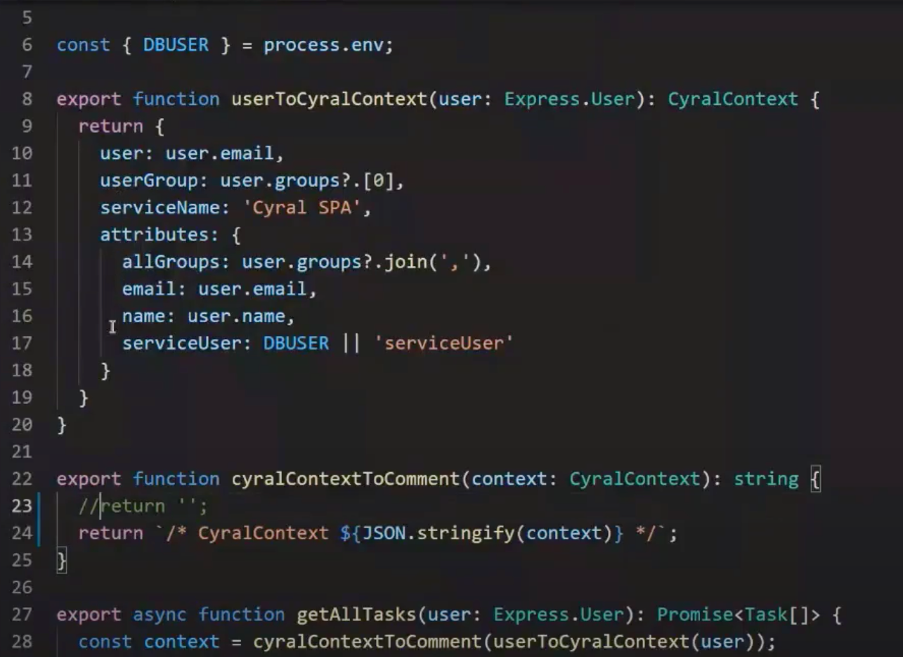
In our application’s data access tier, we’ll add a CyralContext comment at the front of the query. We’ll harvest relevant details from the JWT and pass them to Cyral. Though we could use the JWT to authenticate as we begin a database connection, using this attribution comment allows us to use standard database connection pooling.
The Cyral sidecar takes this attribution comment, validates against the data access policies, logs the request, response, and user identity, and forwards the query to the database.
Other than the machine name, the application believes it’s connecting directly to the database. No awkward client libraries or configuration parameters.
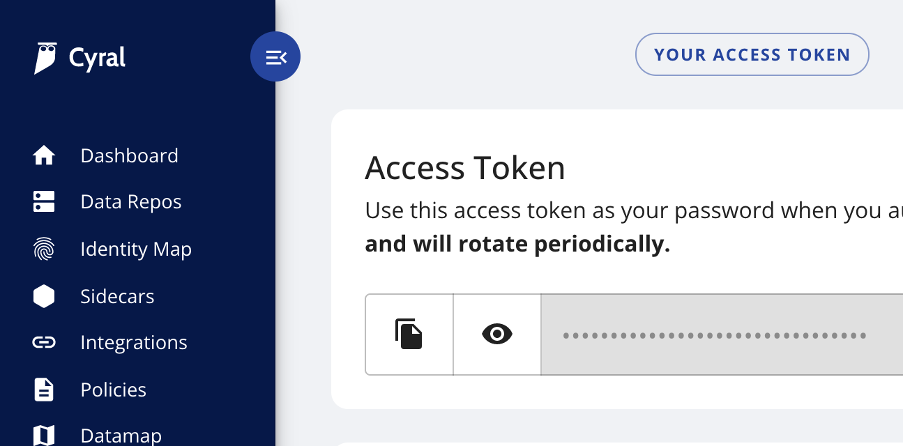
Similarly for non-app uses, we can authenticate to the Cyral sidecar using SSO. The SRE application is linked to the Cyral cluster. Once authenticated via Okta, we can click the “Your Access Token” button, and copy the password. This token is only valid for a few minutes, so we can be confident that our credentials won’t be misused: stuck in a configuration file that might end up in source control.
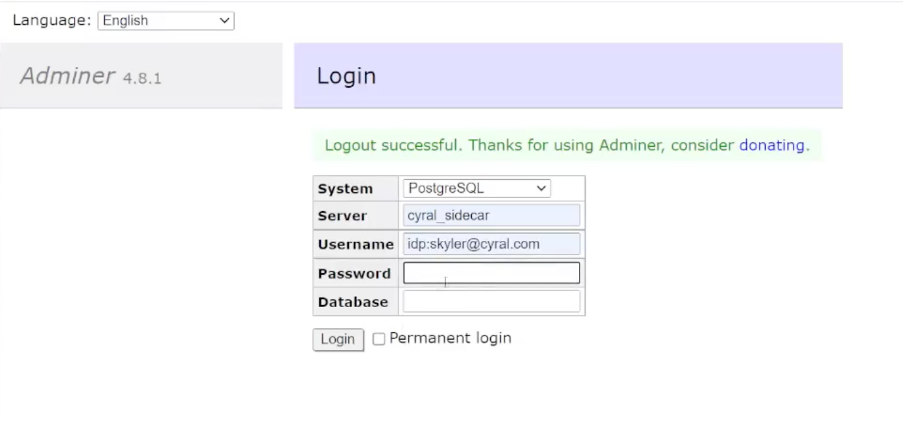
In Adminer, we’ll not login to the database, but rather login to the Cyral sidecar. The username is “idp:” and our email, and the password is the access token we copied from the Cyral control plane. Once logged in, our experience is identical.
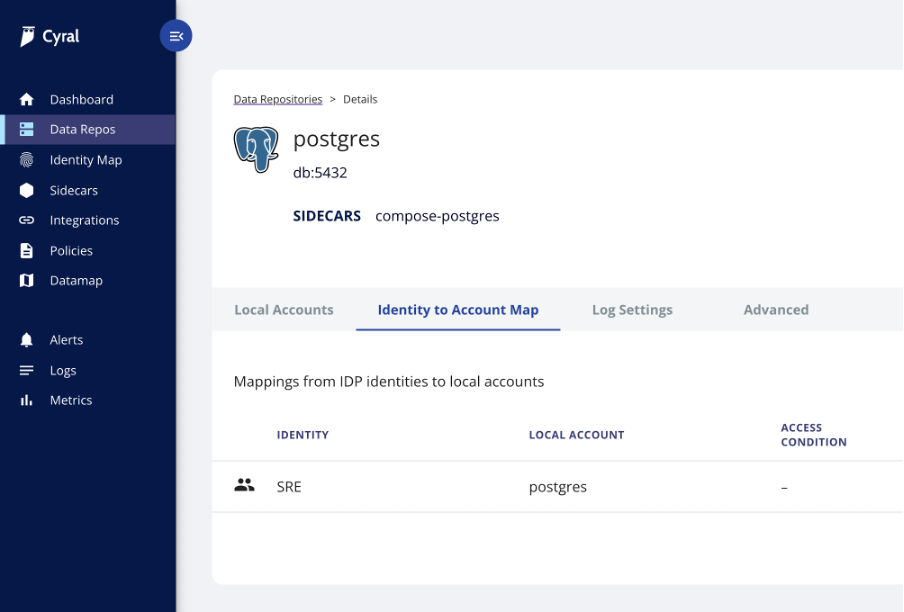
In the Cyral control plane, we can map SSO groups to the database’s service account. In this example, we see our Postgres database will accept connections from users in the SRE group, and use the user named “postgres” to authenticate to the database. This identity mapping ensures we don’t need to litter the database with every SSO user that may come from any source.
Cyral-enriched Logs
In the Cyral dashboard, in the integrations tab, we configured the integration with Okta, the SSO provider. We also configure the integration with a SIEM. In this case we’ve integrated with Splunk. Once configured, logs flow nicely into place in our chosen SIEM.
In Splunk, we chose to load the Okta application. This gives us default dashboards. We could also craft custom dashboards to match specific business needs.
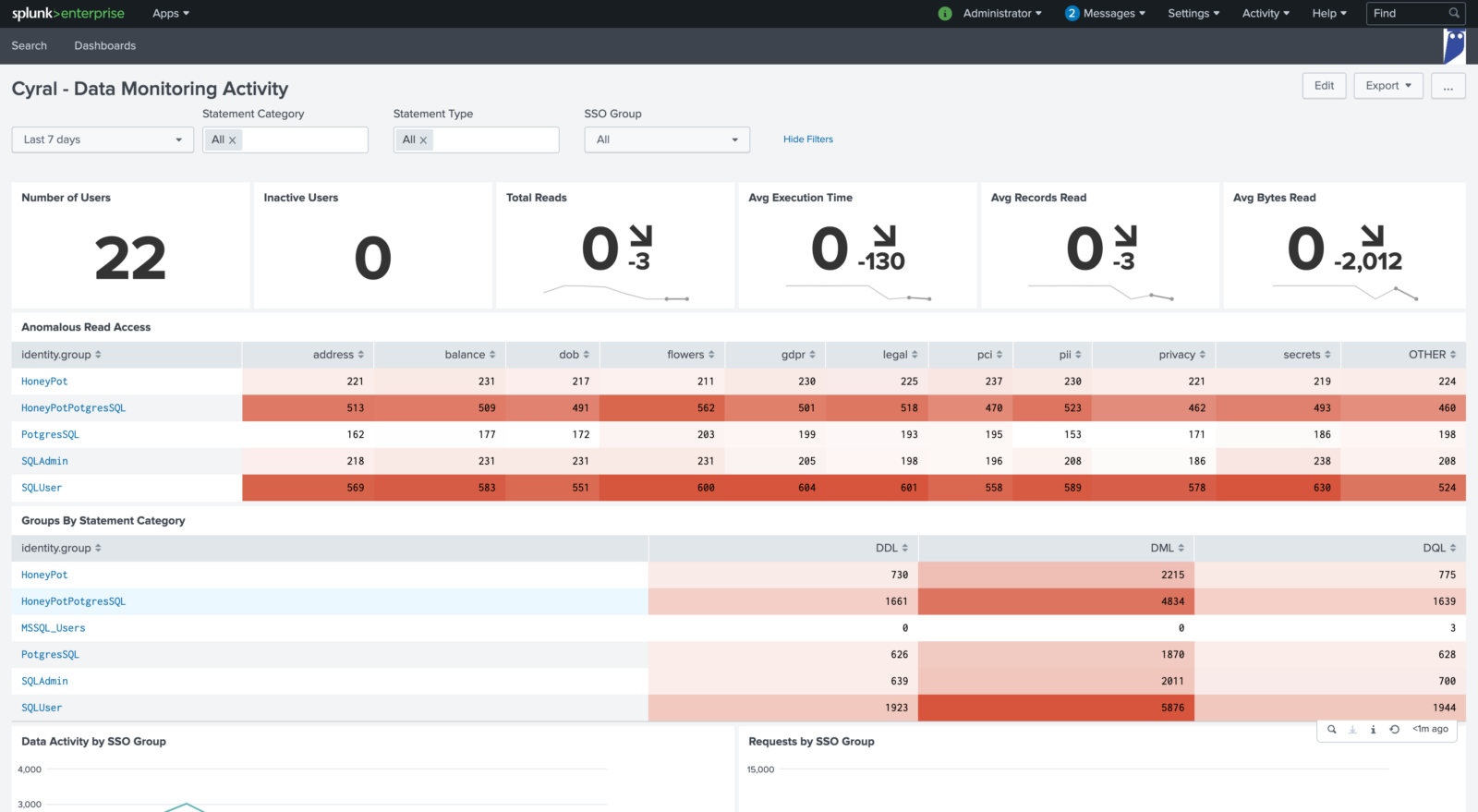
In the Data Monitoring Activity dashboard, we can see aggregated query information and can optionally filter by database, database user, SSO group, or SSO user. In this view we can see that SQL User seems to be doing a lot more queries than others. Let’s investigate.
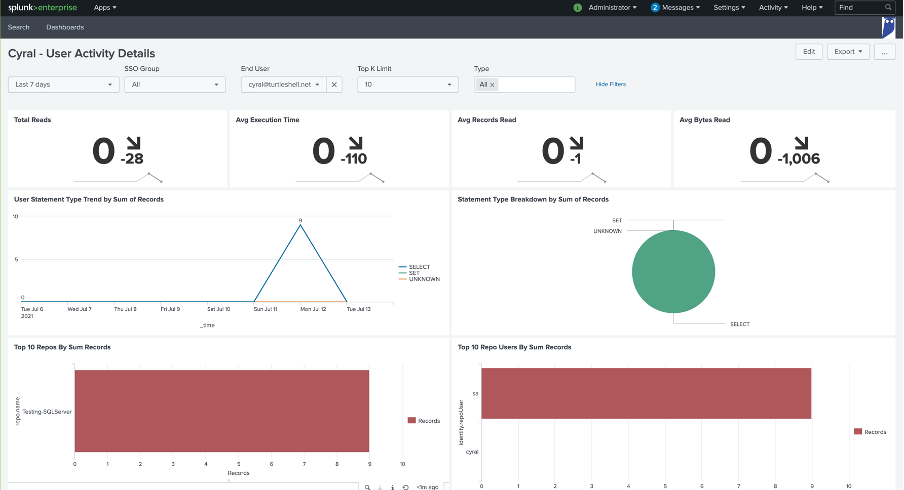
Dialing into the user activity, we can see the types of queries this user has done, and the specific databases used. It looks like they were doing something overnight on July 11. Perhaps this user lost access to their account?
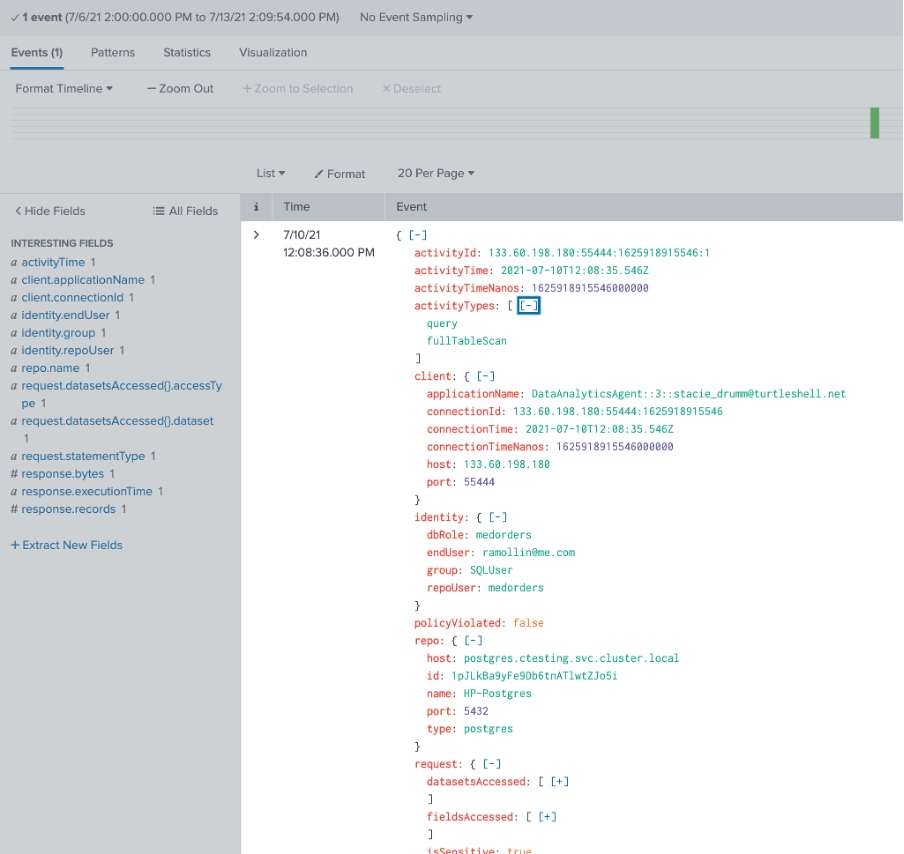
As we zoom into the activity, we can get to the actual database logs. In this picture, we’ve opened up a log entry. We see the query text, the response rows, and specifically the SSO user, the SSO group, and the database user Cyral used as it proxied to the database.
Here in the Cyral logs, we have exactly what we’re looking for: user identity!
The Perfect Solution
Cyral is the perfect solution for answering the question, “Who accessed our data?” With a Cyral sidecar in place, we can authenticate to our database using standard SSO tools. Both application users and non-app uses such as SRE, DBA, and deployment tools can authenticate via SSO. The logs harvested by Cyral include the query request, the response row count, the time taken, connection details like the client IP, and most importantly, the SSO user and group. Who accessed our data? With Cyral, we know.
