
AWS S3 is notorious for exposing confidential data from leaky misconfigured buckets. Common misconfigurations include leaving access to data open to the public, not using SSE (server side encryption), or even leaving a copy of a bucket’s access keys in plaintext in a public GitHub repo!
To be fair, these incidents are indicative of the operational challenges involved in managing a service like S3 that is easy-to-use and automation-friendly. The typical DevOps view of S3 is centered around discussion of its vulnerabilities, and on playbooks to provision, manage, and secure buckets, in a way that both safeguards confidential data, and allows teams to be agile and automation-driven.
Beyond the operational challenges, though, how might an architect or a technologist look at the S3 service itself? Are there examples of successful products that have incorporated it into their architectures in unique ways? What can we learn from its evolution from a Simple Storage Service to being the backbone of modern data infrastructure?
This post is an architect-technologist’s view of S3, and will chronicle the pivotal role it has played as a key architectural component of successful data warehouses and data lakes of the last decade, and the promise it holds for the next generation of data products. We will talk about Snowflake, Databricks, the Modern Data Stack, Data Mesh, and the works. We will also discuss data democratization, data sharing, and the analytics economy along the way!
Excited? Let’s start with a bit of data warehouse history, first!
The Shared-Nothing Architecture
Data warehouses are almost as old as databases (which have been around for decades, themselves), but we’ll tee off from a time around 15 years ago, when the first distributed data warehouses started appearing. These were built on a shared-nothing architecture, and ran as clusters of individual nodes comprising both compute and storage, as opposed to the single-node SMP (Symmetric Multi Processor) data warehouses of the previous generation.
The shared-nothing architecture allowed these products to scale out horizontally to accommodate increased processing demands, whereas the previous generation could only scale up vertically, thus being constrained by Moore’s Law.
There was a fundamental limitation, though! Due to the tight coupling between compute and storage at the node level, it wasn’t possible to scale one independently of the other. Compute resources couldn’t be tailored to the demands of a workload without also impacting storage, and vice versa. Workloads also interfered with each other when they ran since they were all vying for the same shared resources, leading to unpredictable performance.
The key to solving these problems was in breaking the tight coupling between compute and storage. Storage needed to be abstracted out as a service. S3 would eventually make this possible but it didn’t start out that way, though!
Amazon Simple Storage Service is Introduced
AWS released S3 (Simple Storage Service) in 2006, around the same time that the shared-nothing data warehouses architectures were getting popular, but with very different ambitions. Storage was getting cheaper, the internet was growing, and increasingly a managed storage service where people could store their videos, images, spreadsheets, and personal backups made a lot of sense.
S3 was cheap to use, had a simple API, and provided strong durability and availability guarantees. Soon, individuals, website operators, and even very early-stage startups that just wanted to kick the tires on their idea without having to go ahead and spend a ton of money on data centers, started using it for their personal needs, and it took off in a big way.
These use cases drove the first wave of S3’s evolution.
The first wave: A highly available and durable Internet Storage for personal data
It wasn’t until 2012, though, when Snowflake built one of the first cloud data warehouses, that S3 started getting viewed as more than just Internet Storage. In Snowflake’s architecture, S3 was used as the database’s main storage layer, thus naturally decoupling it from compute (which was based on AWS EC2).

Remember, this was exactly what the earlier shared-nothing architectures struggled with? But now because of S3, it was possible to match the processing demands of each workload individually, by provisioning / scaling compute just for it, without impacting either the storage, or the performance of other workloads!
This led to a big shift in how architects and developers viewed S3 but it would still be a few years before it would start becoming the backbone of the modern data infrastructure.
In the meantime, S3 became a sort of landing place for unstructured and semi-structured data sources, such as web server logs, sensor readings, and partner feeds, from where ETL pipelines could read, transform and load the data into analytics platforms. These use cases drove the second wave of S3’s evolution.
The second wave: A holding pattern for unstructured and semi-structured business data
In the last few years, analytics platforms like Spark, Presto, Athena, and Dremio have added varying degrees of support for S3. This has allowed data analysts and scientists to process structured and semi-structured data in S3 buckets in a way that’s very natural for them – abstracting S3 as a relational table, filtering or joining data in an S3 bucket with data from an RDBMS, etc. This has further expanded S3’s reach and utility in the data engineering and analytics communities.
The most significant contribution in recent times, though, has been Delta Lake, built by Databricks in 2021. Delta Lake is an open-source ACID-compliant storage layer with a rich metadata and support for transactions, using AWS S3 (with support for other blob stores also present) for the actual data storage.
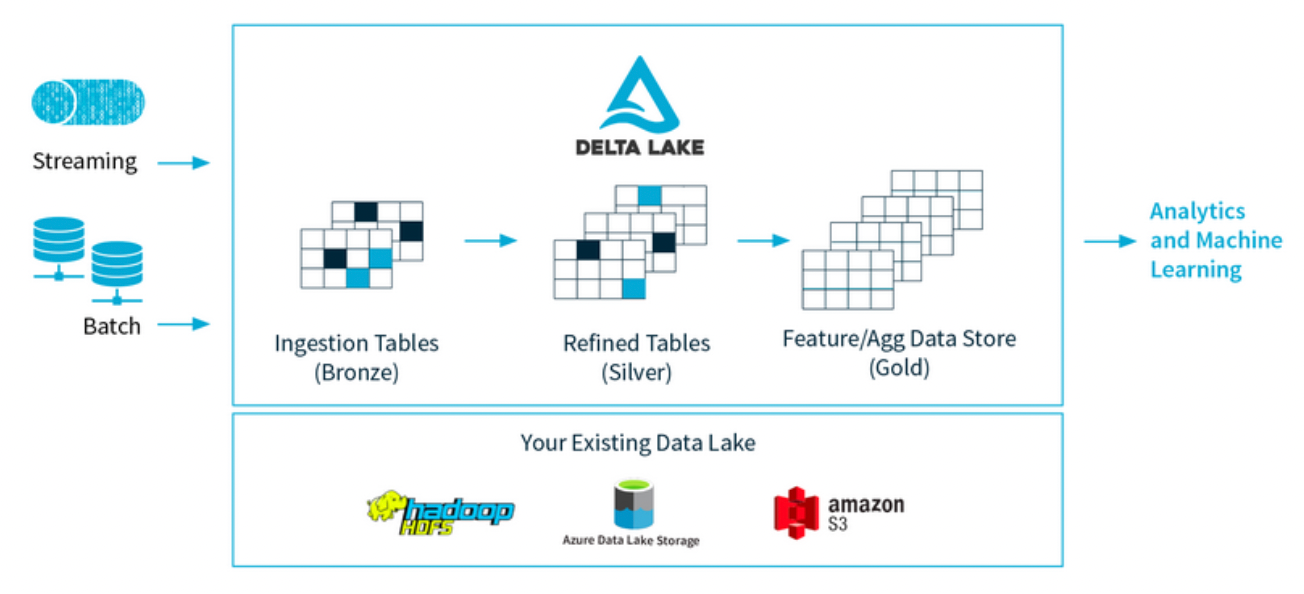
It supports both streaming and batch jobs, and aims to eliminate silos by becoming the single place where all structured, semi-structured, and unstructured data lives!
Why is Delta Lake Significant?
Snowflake’s adoption of S3 back in 2012 was unique; however, the file formats, ACID support, and transactional capabilities were proprietary. It was difficult for architects and developers in other companies to replicate for their projects all the heavy lifting Snowflake had done.
Delta Lake removes this obstacle because it is entirely open-source and uses open file formats like Parquet. Now architects and developers everywhere can leverage it as a fully decoupled ACID-compliant storage layer for all their structured and semi-structured data.
Compute is now truly decoupled from storage!
This decoupling and open-ness also enables data sharing among teams, partners, and customers in ways that was not possible before. Teams can produce or consume Delta Lake data using tools of their choice without worrying about how the other party would be able to access it. The actual process of sharing is also far more efficient because in most cases physical copies of the data don’t need to be made anymore, which is essential at the multi-petabyte scales.
There is currently debate and discussion around the best ways organizations should build their services and organize their data, which would drive them to become more agile and data-driven. This has led to architectures and frameworks such as Data Mesh, the Modern Data Stack, and the Analytics Economy.
The Need for Agile Data Democratization
Their respective philosophies aside, these are all driven by a fundamental need for agile data democratization and data sharing among organizations today. Delta Lake, and other frameworks like it that may come up in the future, are well-suited for such applications, and will drive the next wave of S3’s evolution.
We’ve traced S3’s evolution from being a simple Internet Storage for personal data to being the backbone of the modern data infrastructure. As the use cases grew, S3’s ubiquity has made it vulnerable to misconfigurations, breaches, and attacks. And that brings us back to the point at the beginning of this post, that it’s a huge challenge to provision, manage, and secure S3 buckets, even more so once storage layers like Delta Lake are adopted by organizations for their Modern Data Stack and Data Mesh architectures.
Enabling Non-Technical Users to Use S3 Safely and Simply
In recognition of these challenges, I am incredibly excited about the AWS S3 browser our team at Cyral has launched today. It allows organizations to enable their non-technical users to use S3 in a safe and simple manner.
