

Why Data Security is Broken, And How to Fix It
Protect the Data, Not the Vector
Introduction
Cybersecurity is broken.
Although cybersecurity spending is increasing, it is far outpaced by the cost of cybercrime.
The global cybersecurity software, services, and systems market is predicted to grow from $240.27 billion in 2022 to $345.38 billion by 2026, a 9.5% CAGR, according to Statista. But over a similar timeframe, Cybersecurity Ventures expects the global cost of cybercrime to grow by 15% per year, reaching $10.5 trillion USD annually by 2025, up from $3 trillion USD in 2015.
When we talk about cybercrime costs, we mean the destruction of data, monetary loss, lost productivity, IP theft, theft of personal and financial data, embezzlement, fraud, business disruption, investigation cost, restoration of data and systems, and reputational harm. Widespread, significant, and existential damage.

Organizations, cities, and governments are spending more, but it’s not enough–and it’s not working.
Why? Because they are fighting a losing battle to protect attack vectors, rather than securing the hacker’s target – the data. They’re playing whack-a-mole to stop bad actors from coming in, but the stakes are too high for that game. And they are losing.
It’s time for a rethink. It’s time to protect the data, not just the vector. And that’s what this guide is all about. How we got here, and more importantly where we go next.
How is Data Created?
Let’s start at the beginning by looking at three distinct ways that data is ‘born’.
Applications
Applications generate vast amounts of data of various types. Each time an application is used, data is created or updated. To explain how this happens, let’s look at a few examples of common apps we all know and use. Through the following examples, we’ll also explain the various types of data being created – primary data that are proactively created, and secondary data created as a result of the primary one.
Let’s start with email, an app that we all use. Whether you use Outlook, Google Workspace, Apple Mail, or a different email app – the principle is the same. The primary type of data is created when you write a new email or respond to someone; by doing that, you have created new data (i.e., content).
However, even if you’re only reading emails, there is still secondary data created in the background. It is called metadata, which is data that provides information about other data. For example, metadata keeps track of whether you’ve already read a certain email message (and hence metadata marks it as “Read”), or you haven’t yet read that email, and it’s “Unread.” Metadata also keeps track of many other things, such as who sent the email, at what time, from where, the route that the email took to get to you, and much more.
Exactly the same rule applies to online apps. You’ve logged into your bank account in order to view your account status and didn’t perform a single proactive transaction. The app would still register the exact time you logged in, the IP address from which you connected, and similar metadata. If you’ve shopped on Amazon, bought event tickets on Ticketmaster, or paid for parking using BestParking, in addition to creating data on the proactive transaction you performed (shopping, payment, etc.), the app would register metadata from the transactions you performed – date, time, the amount paid, method of payment, IP address, etc.
Systems of Record
According to Bain Capital’s Ajay Agrawal, “A system of record (SOR) is software that serves as the backbone for a particular business process”. The System of Record (SOR) serves as an authoritative source of truth, helping organizations manage the vast amounts of data that characterize modern work life. There are multiple SORs in each company for various uses such as finance, HR, customer data, and more.
Traditionally, companies operated fewer SORs and tried to combine as many functions as possible (for example, combining finance with customer data). However, the Internet revolution and new SaaS software models have led to SORs starting to specialize in specific fields. There are now major categories for SORs: Finance (e.g. SAP, Intuit), HR (e.g. Workday), Customers (e.g. Salesforce), IT (e.g. ServiceNow), and Operations (e.g. Adobe Workfront). There are additional SORs that serve specific industries, such as Insurance (e.g. Guidewire), Life Science (e.g. Veeva), Higher Ed (e.g. Ellucian Banner, Oracle PeopleSoft), and more.
Devices / IOT
Many “things” we use in our daily life generate data without us even thinking about it. Such things include our cellphones, smartwatches and other wearable devices, smart TVs, gaming consoles, and other electronics connected to the Internet. These things generate various types of information, depending on their role. They track and remember our location; they record our pulse, heart rate, and other human vitals; they remember and learn our preferences.
Other things are also data generators. Smart cars connected to the Internet are one example. There are already millions of connected cars around the world. Smart homes are another example – the home that learns our preferences and adapts its systems to our needs (turning on/off the lights, adjusting room temperature to our preference, and much more). Smart refrigerators that issue online orders by themselves to the nearest supermarket.
And there’s much more. ATM machines are connected to the Internet. Traffic lights. Entire factories and the machines within them. Security and video surveillance devices. Airplanes, ships, trains, and additional types of transportation. One interesting example – when the Russian army invaded Ukraine in early 2022, it stole a large number of new John Deere agricultural equipment from Ukraine; however, after moving that equipment to Russia on trains, the Russians couldn’t get the tractors and other equipment to start working, because everything was remotely disabled from John Deere’s US headquarters. John Deere knew exactly where the equipment was, and what was stolen because each piece of equipment has a GPS device that’s connected to the Internet and broadcasts information.
The Internet of Things phenomenon is growing at an exponential rate. In 2022, it is estimated that anywhere between 10 and 15 billion devices are connected to the Internet. This number is already higher than the world’s population, which is short of 8 billion people. By 2025, it is projected that the number of connected devices will reach between 27 and 64 billion! That’s a huge number of connected devices, all generating data.
How much data does IoT generate? Research firm IDC predicts that data collected from IoT devices in 2025 will be 73 ZB, most of it from security and video surveillance and industrial IoT applications.
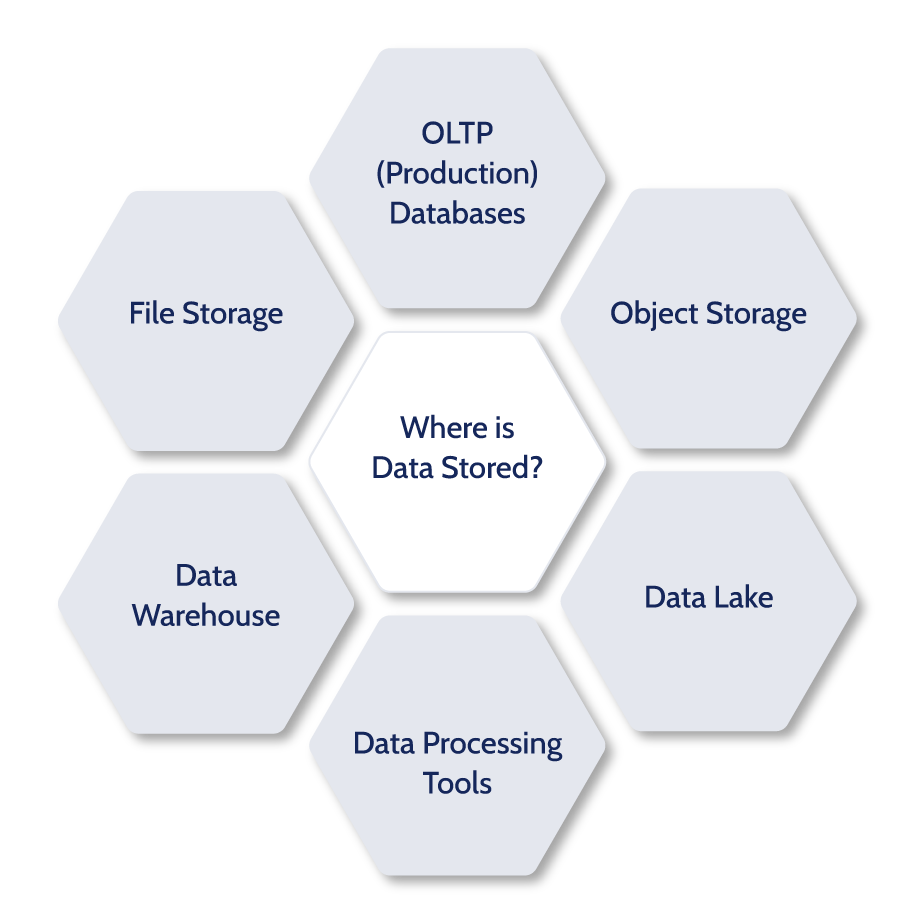
Where is Data Stored?
Once business data is created, there are various places, or data stores, where that data can be kept. The first category is Primary, which has two types of data stores: (1) OLTP (Production) Databases, and (2) File and Object Storage. In addition, there is the category of Secondary data stores, which are extensions of the primary data stores. There are three types of secondary data stores: (i) Data Warehouse, (ii) Data Lakes, and (iii) Data Processing Platforms. In this section, we’ll explain what each of these is, its role, and how they differ from one another.
Primary Data Stores
OLTP (Production) Databases
OLTP stands for On-Line Transaction Processing. It is a type of data processing that involves real-time execution of a large number of transactions, done by a large number of people. These transactions are executed in parallel, typically over the Internet. Each transaction changes, inserts, deletes, or queries data in the database. An important characteristic of OLTP is that the transaction can either succeed as a whole, or fail, or get canceled. It cannot remain pending or in an intermediate state.
Generally speaking, an OLTP database is where the business’ production data is stored – data about customers, products, etc. Typically, an OLTP database will also include Personally Identifiable Information (PII), meaning fields such as customer names, email addresses, possibly physical addresses, phone numbers, and similar PII. The PII data is important because it’s the most sensitive type of data we want to protect.
Various apps may interact with an OLTP database – both internal apps operated by employees and external apps operated by the business’ customers, partners, or suppliers. Each interaction with the database is a transaction. These transactions can be either internal or external. An internal transaction can be of various types, such as an employee performing a query to decide which customers will receive a new promotion. External transactions can also be of various types, such as customers performing shopping, performing online banking, sending text messages, and much more. No matter the transaction – all transactions are recorded and secured, so enterprise employees can access that information at any time for various purposes (accounting, reporting, etc.). In some cases, customers can also access some information, such as checking their purchase history at that business.
OLTP databases, and the transactions they enable, are responsible for many of the financial transactions we make every day. These include things such as online banking; ATM transactions; in-store purchases; online shopping/e-commerce; booking of hotels, cars and airlines; and much more. In addition to financial transactions, OLTP databases can also drive non-financial activity, such as sending text messages on our mobile devices; or managing a password repository, including enabling us to change our passwords.
A web, mobile, or enterprise application typically tracks transactions (or interactions) done with customers, suppliers, and/or partners. Then, it updates these transactions in the OLTP database. That transaction data, stored in the database, is critical for ongoing business activities. Moreover, this data is used for reporting or analysis to support data-driven decision-making.
Generally speaking, OLTP databases:
- Process a large number of simple transactions: insert, update or delete data, as well as data queries (such as getting your checking balance at your online banking app).
- Enable many users to access the same data while ensuring data integrity simultaneously. OLTP systems ensure that no two users can change the same data at the same time, and that all transactions are carried in proper order. This, for example, prevents the same hotel room from being double-booked by different people. It also protects the owners of a joint bank account from accidental overdrafts due to simultaneous money withdrawals.
- Allow for extremely rapid processing of transactions. The response times on OLTP databases are measured in milliseconds. In fact, an OLTP database’s effectiveness is measured by the total number of transactions it can carry out per second. The higher the number, the better and more effective the OLTP database is.
- Offer indexed data sets. These enable rapid search, retrieval, and query of the data.
- Provide 24/7 operations and accessibility. OLTP databases process huge numbers of concurrent transactions, and often critical transactions (financial, for example). This means that any downtime can result in significant, costly repercussions to the business and its customers. There must be a complete data backup that is available at any moment in time. Hence, OLTP databases require frequent, regular backups, as well as constant incremental backups.
File / Object Storage
These are storage systems that retain every type of data that a business uses for ongoing operations. Let’s see what each type is and the difference between them.
File Storage
File storage is what we all have on our laptops. It is a hierarchical model where the data is stored in files, and the files are organized in folders. The folders themselves are organized in a hierarchy of directories and subdirectories. If you want to find a file, you need to know the exact file and the path to get to it. This means starting from the main directory and getting to the specific subdirectory (folder) where the file is located.
The File storage model is used for our computer hard drives, and also for network-attached storage (NAS) devices. This hierarchical model works well when you have easily organized amounts of structured data. Structured data means that the data is in a standardized format and has a well-defined schema. For example, all my Excel files with annual projections; or all the Word files with customer success stories.
The key issue with File storage is that when the number of files grows, finding a file and retrieving it can become cumbersome and time-consuming. To scale a file storage system, we need to add more hardware devices or replace our existing hardware with higher-capacity drives (disks) – both options are costly.
One way of mitigating the scaling and performance issues is to use cloud-based file storage services. Some well-known cloud-based file services include Google Drive, Microsoft OneDrive, Apple iCloud Drive, IDrive, Dropbox, Box, and more. These services allow multiple users to access and share the same file, located in the cloud. These services typically work on an OpEx model, where you pay a monthly fee for the amount of storage you need. If you need more space, you can easily scale up for a small amount without heavy upfront investments. You can also have several tiers of payment, based on criteria like performance and protection – according to your needs.
Such a service, also known as Infrastructure-as-a-Services (IaaS), allows you more flexibility and agility. It also eliminates your big, up-front CapEx expenses, which include but are not limited to maintaining your own on-premises datacenter, and upfront purchases of the storage hardware you need. With cloud-based storage, all these CapEx expenses are gone.
Object Storage
Object storage is used to store huge, unprecedented amounts of unstructured data. Unstructured refers to datasets – large collections of files – that are not arranged according to a pre-set data model or schema. Because of that, unstructured data cannot be stored in a traditional relational database (RDBMS). An OLTP database, which we discussed earlier, is the predominant use case for an RDBMS.
We all know samples of unstructured data from our daily lives. Text and multimedia are two common types of unstructured data. There is a lot of unstructured data in daily business life – think about email messages, web pages, social media, videos, audio files, photos, imaging data, sensor data, digital surveillance, scientific data, and much more. Unstructured data is the most common and abundant type of data in the modern world. You can store people’s names, addresses, zip codes, and additional information in a database; but you cannot typically store unstructured data in the same database.
Object storage is a data storage architecture used to store unstructured data. Each piece of data is designated as an ‘object’ kept in a separate storehouse and bundled with metadata and a unique identifier for easy access and retrieval. Objects can either be stored on-premises or in the cloud. Typically, the latter option is chosen, so the objects are easily accessible from anywhere. Object storage literally has no limits to scalability, and it’s a far less costly method—compared to File storage—to store huge data volumes. A few of the most well-known object storage systems include Amazon S3, Google Cloud Storage (GCS), Azure Blob Storage, StackPath, Alibaba Cloud Object Storage Service, and more.
So what is the difference between file storage and object storage? The short answer is that these are different storage formats for holding, organizing and presenting data. Each method has its pros and cons, as each was designed and specifically tailored for a certain type of data. There is no good, bad, or better storage format – it all depends on the specific use case. File storage stores data as a single piece of information (i.e. file) and that file is stored within a hierarchy of directories and subdirectories. Object storage takes each piece of data, designates it as an object, and bundles it with the associated metadata and a unique identifier.
Since we mentioned cloud-based data storage options, it is important to note that while these systems have various data security features – these controls are configuration options. The user who defines these cloud-based data storage systems needs to intentionally set the data security controls, in order to provide access control to the objects. If you don’t set these security controls correctly, your data may be exposed to the world. We’ll return to this point later on.
Secondary Data Stores
In addition to the primary data stores, there are also a few secondary data stores that organizations use for various purposes.
Data Warehouse
A data warehouse is a data management system that centralizes and consolidates large amounts of structured data from multiple sources. A data warehouse is solely designed to perform business intelligence (BI) activities – queries and analysis – allowing the organization to analyze the data and make informed decisions. For example, a data warehouse will serve for deriving repeatable analysis and reports such as a monthly sales report, tracking of sales per region, or analyzing website traffic.
Data warehouse is not a place where data gets created, hence why we call it a ‘secondary’ data source. The data is transferred to the data warehouse from databases, application log files, transaction applications, and possible other ‘primary’ data sources where the data is created. The data is usually transferred on a regular cadence and kept for a long time – to gather historical data for analysis.
Data and analytics have become critical for businesses to stay competitive. Business users rely on reports, dashboards, and analytics tools to extract insights from their data, monitor business performance, and support good decision-making. It’s impractical to generate such business tools from the actual production databases. In order to keep databases highly performant, they are constantly truncated in order to keep their tables minimized. Any analysis done on the actual database would (1) be done on a relatively small amount of data; (2) negatively affect the database performance for live work; and (3) only take into consideration the data in that specific database, whereas the organization often needs to consolidate data from multiple data sources in order to generate good reports and dashboards.
Data warehouses were designed to solve all of the above-mentioned challenges. They consolidate and store all the data, from various databases and sources, and then perform data queries to the aggregated data. Data warehouses are designed to store the data efficiently and minimize the I/O in order to deliver fast query results to business users.
Data Lake
A data lake is very similar to a data warehouse, in the sense that it serves as a centralized repository to store, process and secure large amounts of data from various sources. The goal is to later run different types of analytics on that data, including dashboards, visualizations, big data processing and so on – to allow for better decision making.
The main difference between data warehouses and data lakes is that the former only allows for storing of structured data, such as data flowing from relational databases. Data lakes, on the other hand, allow you to store all of your data – structured, semi-structured and unstructured data – at any scale. Data lakes enable you to store the data as-is without first having to structure that data. Then, you can run analytics on all of that data, including the unstructured portions.
The ability to also store unstructured data allows businesses running a data lake to include in their analytics all types of unstructured sources such as log files, social media, or internet-connected devices, to name a few.
While data warehouses and data lakes both store data in some capacity, with the goal of analyzing that data and deriving business decisions – they are complementary tools, not competing ones. Each tool is optimized for different needs and use cases, and many organizations will use both a data warehouse and a data lake, depending on the specific use case. It’s not that a data lake is ‘better’ just because it can also store and analyze unstructured data.
Data Processing Tools
These tools take data from the ‘primary’ data sources and move them to the ‘secondary’ data sources – data warehouses and data lakes – while ideally, they should omit any sensitive data along the way, such as PII.
Data processing tools take the data from the primary and move it to the secondary – data warehouse and data lakes – and should omit the PII along the way. The challenge in real-life scenarios is that companies are not always using them in that way.
We’ve seen many cases where data warehouse and data lake vendors told customers: “Why don’t you just transfer all the data you have in your databases to our data warehouses and data lakes? Then you could do data mining, run queries, and get all sorts of flexible data analytics that you cannot do today on your databases.”
And, in many cases we saw, customer teams took that advice in a literal way and did exactly that – transferring and dumping all data from their production databases and other systems; and they did so without any filtering or redaction of highly sensitive information. So, companies’ data warehouses and data lakes are filled with sensitive information that should have never left the production systems, as it should have been redacted during the transfer job. Obviously, having sensitive information in data warehouses and data lakes creates a major enterprise data security and data leakage hazard to the organization, as it exposes the data to people who may not be privileged to view it, plus the additional hazard of external attacks on an additional data source.
Enter the Modern Data Stack
Let’s look at the definitions for some of the more popular tech trends, and then look for commonalities. The first three definitions are Gartner’s; the last one, for Data Democratization, is from a Forbes article:
Digital Transformation: refers to anything from IT modernization (for example, cloud computing), to digital optimization, to the invention of new digital business models. The term is widely used in public-sector organizations to refer to modest initiatives such as putting services online or legacy modernization. Thus, the term is more like “digitization” than “digital business transformation.”
Cloud Migration: the process of consolidating and transferring a collection of workloads. Workloads can include emails, files, calendars, document types, related metadata, instant messages, applications, user permissions, compound structure and linked components. Migration of such workloads from at least one permanent on-premises platform or cloud office to a new cloud office environment, across a variety of similar product classes, is typical. During the migration process, enterprises will choose to cleanse their existing platforms by archiving old and outdated data. Migration tools are able to conduct an analysis of the respective workloads, identify if the data is deemed suitable for migration while maintaining its integrity, migrate the data between the source and target, and ensure governance in the subsequent platform.
Application Modernization: migration of legacy to new applications or platforms, including the integration of new functionality to provide the latest features to the business. Modernization options include re-platforming, re-hosting, recoding, rearchitecting, re-engineering, interoperability, replacement and retirement, as well as changes to the application architecture to clarify which option should be selected.
Data Democratization: everybody has access to data and there are no gatekeepers that create a bottleneck at the gateway to the data. It requires that we accompany the access with an easy way for people to understand the data so that they can use it to expedite decision-making and uncover opportunities for an organization. The goal is to have anybody use data at any time to make decisions with no barriers to access or understanding.
Explosion in Data
If you think about the above concepts and their definitions, you quickly realize it’s all about data. More precisely, it’s about better aligning data and everything around it – infrastructure, applications, processes and more – so data is easier to use. The goal, of course, is to derive better decision-making from this data.
This explosion in data has various aspects. The first and most obvious one is that we all create significantly bigger amounts of data, and that the data creation rate is increasing every year.
Another aspect is that the number of available data stores increases; each organization uses an increasing number of data stores every year. More specialized data stores give organizations more flexibility to achieve their goals. Who thought about Snowflake a few years ago? Or Amazon S3, for that matter? Life was much ‘simpler’ a decade or two ago when you only had an Oracle database (or an IBM Db2).
The more data there is across more data stores results in more people and applications needing access to all of these data stores. After all, the end goal is to enable all the additional data and data stores to people and applications, so they can perform a better job.
Increased Complexity
Everything we covered significantly increases the risk of data exposure to the organization. The increase in the number and spread of data stores, across various clouds and platforms, means that potential bad actors have a significantly higher number of attack surfaces to utilize. They don’t need to find security holes in each and every one of your data platforms; all they need is to find a hole in one place that leads to sensitive information.
In addition, an increasing number of data stores means you need to manage a much larger number of configurations. Doing all that work manually, as is typical in today’s organizations, is challenging and becomes an almost impossible mission. Not only does configuring everything manually become almost impossible when it comes to manpower and related workloads, but the risk of misconfigurations also increases in a significant manner. Again, all a hacker needs to do is find a hole somewhere, for misconfigured credentials of a single user, for a single data store. This is what hackers specialize in. How can the organization’s security team protect all of the additional data stores, against all the additional attack vectors and possible misconfigurations?
Threat to Data Security
Why data security? And why now?
That’s the billion-dollar question.
To answer that, let’s look at what changes took place in the data security world over the past five years, and use that to extrapolate into the future, five years from now. We’ll look at 2017, compare it to present 2022, and attempt to make educated guesses for 2027.
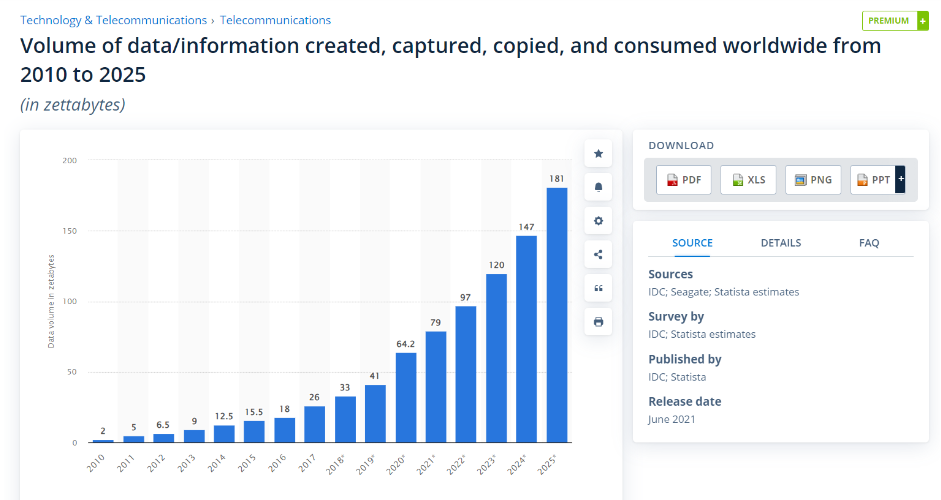
5 years ago (2017). According to Statista, a global provider of market and consumer data, the volume of data/information created, captured, copied, and consumed worldwide in 2017 was 26 zettabytes. Many data clouds were small companies back then, having been founded over the last 10-15 years. This includes companies such as Snowflake, Databricks, and Cloudera. Even cloud giants such as Amazon Web Services, Microsoft Azure, or Google Cloud were relatively tiny in 2017, compared to the present.
Today (2022). Recent years brought an explosion in both the volume of data, as well as the number of data clouds and data providers. According to Statista, the total volume of data created, copied, and consumed in 2022 is estimated to be 97 zettabytes, meaning a growth of ~4x in the amount of data in just 5 years. In addition, there are many more cloud-based providers today, with each one being significantly bigger, compared to five years ago. This includes companies we already mentioned, other enterprises that significantly invested in and increased their cloud offerings (Oracle, IBM, Alibaba, etc.), as well as the exponential growth of the large three hyperscalers – AWS, Azure, and Google Cloud. If we take just AWS, we can see that its revenues grew from ~ $17 billion in 2017 to a run rate of $74 billion in 2022 – a growth of more than 4x. We can assume the growth in data stored on AWS grew by at least that much, and probably significantly more, as the cost of a storage unit (dollars per terabyte) has also drastically declined over the past five years.
It’s not just the explosion of data and vendors but also the way organizations changed their working methods. Back in 2017, most organizations stored most of their data, and specifically critical data, in on-premises data centers or private clouds. It was extremely rare to see an organization running mission-critical applications and data such as SAP ERP on a public cloud. However, the last five years have seen an explosion in organizations moving data and applications to the cloud, and increasing the use of dedicated data platforms. Salesforce, for example, tripled its revenue during these last five years as an increasing number of organizations started using its platform. Same with other cloud data platforms.
5 years from now (2027). This is anybody’s guess. Statista estimates 181 zettabytes in 2025, the furthest-most year it forecasts. Based on growth rates, the number for 2027 will probably be around 250 zettabytes, possibly higher. There will also surely be many more cloud data platforms, including giant ones that are barely noticeable today (like some major ones were barely known in 2017). Moreover, we assume the number of data platforms that each organization will operate in parallel will also grow exponentially – making it harder for the organization to keep tabs on its sensitive data and data leakage prevention.
Data Stores – Always the Target
There are many ways a hacker can enter your organization. Some famous hacking attacks in history used phishing emails combined with malware; infiltration through an API that connected the database to other, less secure systems; websites that weren’t well secured, and which allowed access to backend documents and data; accessing the target system through an unpatched vendor software; accessing through third party vendors connected to the target system; using weak credentials to guess employees access and enter the attacked system, and/or leveraging social engineering to have the employee give their credentials to the hacker; and more.
There is one interesting fact when looking at the above list – the attack vector is just that, a vector. The method and attack vector used to infiltrate the organization are never the end goal; rather, the end goal is almost always the data, meaning the database and other data stores in the organization. After all, what can a hacker achieve by simply hacking the network or an insecure API? The hacker is looking for ‘something’ to monetize – and that ‘something’ is almost always the data.
All Roads Lead to the Data
So, it doesn’t matter what attack vector the hacker uses – compromised apps, APIs, credentials, clouds, networks. These are just attack vectors or roads, and they all lead to the same place – the corporate data stores that include highly sensitive data.
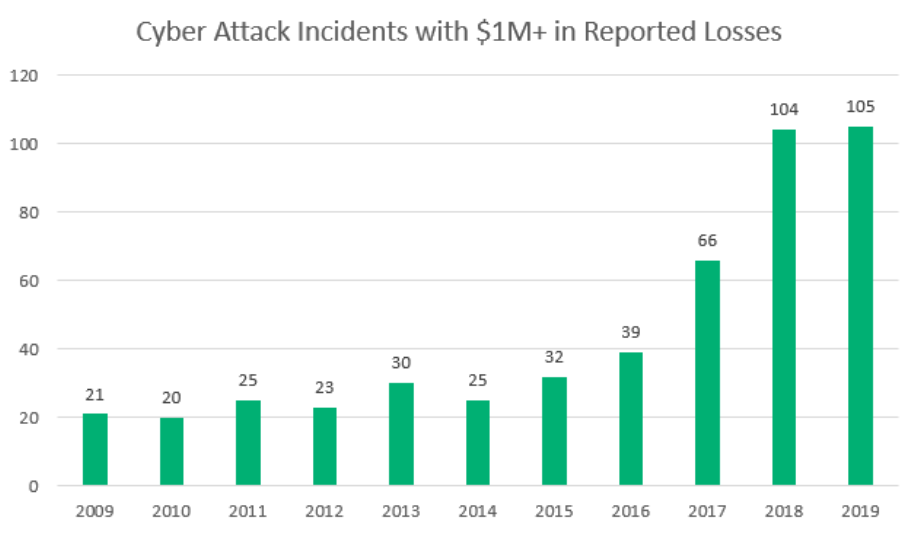
Record High Numbers of Data Breaches and Data Leaks
Today, the number of possible attack vectors constantly increases, as does the number of attacks and the associated damage. Look at this graph from “The Center for Strategic & International Studies (CSIS)” an American bipartisan, nonprofit policy research organization dedicated to advancing practical ideas to address the world’s greatest challenges, including cyber security. Among other things, CSIS tracks cyber-attacks. The following graph is a bit dated, but look at the jump in major cyber attacks between 2009 and 2019, and have no doubt, that trend continued and even increased after 2019, especially given the COVID pandemic and most of the world moving to remote work:
And now, consider how we’re trying to deal with this cyber security pandemic. Think about the number of cyber security tools and resources your organization leverages today compared to a decade ago or even five years ago – the number of clouds used, networks, data stores, applications, APIs, credentials, etc. All these have grown exponentially, yet the security industry still tries to plug new holes that keep breaking the dam. We constantly hear about new cyber security solutions aimed at tackling this attack vector or a different attack vector, yet almost no one looks at the hackers’ end goal – the data stores – and how to protect them directly.
That’s where Cyral’s data protection solution comes in!
The Gap in Data Security Controls
Let’s discuss the challenges with security controls for databases; it’s not that databases lack any security controls whatsoever. In fact, databases will often allow the admin to set some security constraints, such as not allowing a user to read a certain table or certain columns.
There are two issues with databases’ internal security controls. The first challenge makes these security controls ineffective or non-existent. The second challenge is the inconsistency of these security controls between databases. Cyral’s solution solves both.
Ineffective or Non-existent Data Security Controls
This is the minor issue of the two. The challenge with database security controls is that implementing them is very complex and time-consuming for very busy admins. The result, which we’ve seen over many years and in many organizations, is that admins do not correctly implement these controls – which in essence renders them non-existent.
Inconsistent Data Security Controls
Consider a standard organization. It probably has multiple databases for various use cases – Oracle, MS SQL Server, MySQL, PostgreSQL, MongoDB, IBM Db2, and others. Most companies will have a few of those.
The challenge is that each of these databases has completely different methods for implementing its own internal security controls. This means that if you want to correctly implement granular controls to your databases, making sure they’re well protected, then you need people who are highly skilled in each and every database AND fully understand the security configurations for each of these different platforms.
In the ‘old’ days, we used to have dedicated DBAs for each database, who specialized in a specific platform. It was common to have an MS SQL Server DBA or an Oracle DBA. The basic concepts translate from one database to another; for example, if a specific table has social security numbers, then all DBAs would say that you want to block/limit access to such data. However, the method to actually implement such a block/limit is different in each database platform, and that’s what these experts did.
Today, in many organizations, users can initiate new cloud databases for various uses. Organizations use various cloud-based services, so data are scattered across different databases and services. Who will supervise and administer the use of all these?
This is where Cyral comes in. Cyral provides one standard way to define data security controls and make them consistent across all the different database backends your organization runs. You no longer need to think about how to add these controls to MySQL and how to do so differently for PostgreSQL. If you have both these databases in your environment, you define the control once in Cyral. Then Cyral tells the different databases what to do – making sure all the databases adhere to the same security policies that you’ve defined.
It’s straightforward to define these policies in Cyral. We have our own policy language, expressed in YAML. It’s a logical language that understands things such as “I don’t want anyone to be able to query social security numbers” or “if querying a table that has social security numbers, then the numbers should be redacted.” Such policies, which are complicated to express and implement in individual databases’ security controls, are easy to implement in Cyral.
Here’s a simple use case. Say you have a single database with just five different tables. Across these five tables, you have some columns with social security numbers (or any other type of sensitive information, such as credit card numbers). Now, you want to give that database the following command: “No matter which table or column – if you have a social security number, do not allow that number to be returned in a query.” Unfortunately, there is no easy way to directly tell the above command to the database when using its own internal security controls.
However, when using Cyral, you can tag a specific column in the database and say: “this column contains social security numbers” or “this column contains credit card numbers.” Then, in our policy engine, we can express “do not allow to return social security numbers.” We don’t need to perform any mapping or tag each column individually – the engine will recognize similar columns in other tables and know that they are ‘forbidden’ to be returned.
Simple, friendly, powerful, and secure!
And just to clarify: Cyral still enables you to manually flag any column that you want. Cyral offers sophisticated tools that assist in identifying these sensitive columns. The Cyral engine will surface and present these columns to the administrator, so they can then check them, confirm the tools’ assumption that these columns contain sensitive information, and apply security policies.
Due to everything we covered regarding inconsistency and complexity, we find in the field, within databases natively, either ineffective controls or only a few controls have been implemented. Cyral solves all these inconsistency and complexity challenges through applying the same policies to all databases via a central engine; and handling all the databases’ backend through Cyral, without you having to worry about database native security configurations.
Modern Approach to Data Security
The modern data security approach includes three basic elements for database security – authentication, authorization, and auditing.
Database Security Methodology
Authentication
One of the challenges with authentication is that databases typically don’t have an easy way to connect corporate identities with the database login information. Companies often have to create unique user accounts within the database platforms. Doing so causes a problem because those database accounts are not managed/federated consistently through the company’s existing identity provider (such as Okta).
Currently, there is no way for existing authentication tools – such as Ping or Duo Security – to authenticate a user into a specific database. That’s a huge issue when authenticating users’ access to databases.
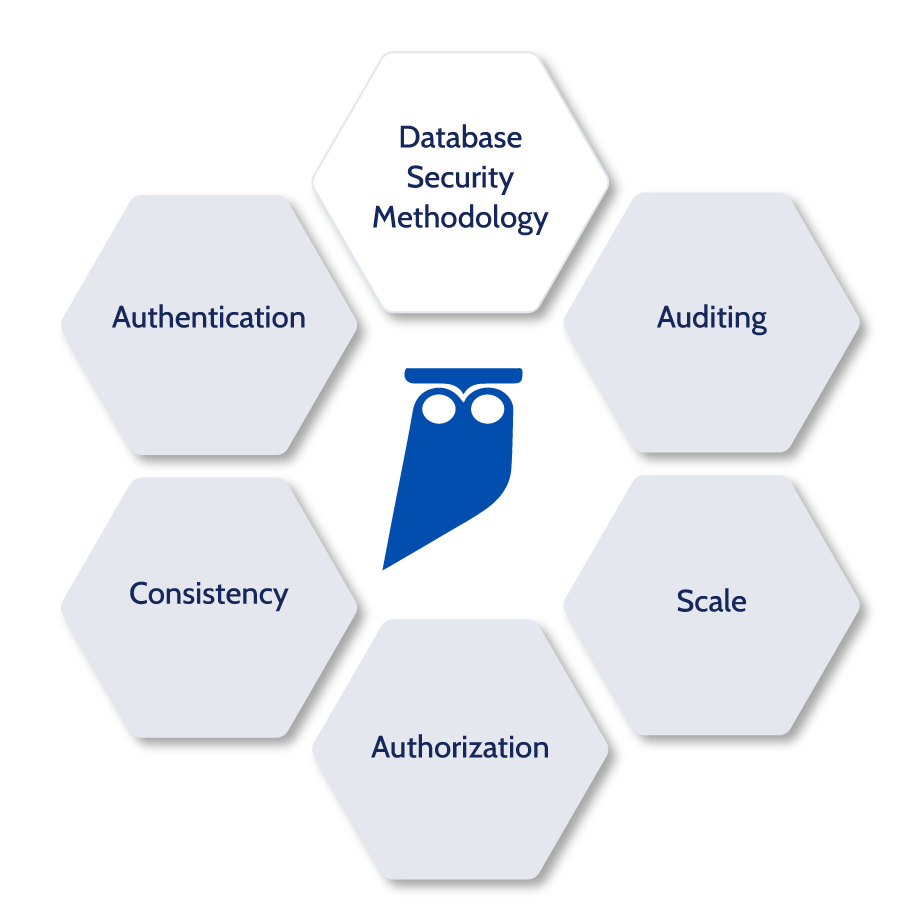
Authorization
Similar to the case with authentication, where there is no easy integration between the federator and the database, there is a similar inconsistency of security controls regarding authorization. First, you have to wrestle with how to map these requirements to users, because there’s no user federation; you also have to deal with how to add selective controls. Both of these are a challenge.
When speaking of ‘selective controls’, think of an example – you want to authorize a user’s access to a particular table in a database, so she can perform her job. However, that user should not have access to sensitive data such as social security numbers or credit card numbers; hence you want to give her restrictive access to the table – view everything, except for the columns with the sensitive data. There’s no easy way to do that today, but Cyral enables all that through our policy engine.
Auditing
It is important to understand who is accessing what data, from where, and when. This is what good logging provides – the ability to audit everything that’s happening – and why we want to log as much as possible. The database platforms can log all queries to a given database; however, this will typically come with a severe impact on the database performance, making it hard to use these internal database capabilities.
To summarize, we covered in this section the modern approach for securing data on your databases, which includes authentication, authorization, and auditing. For authentication, you want to tie back to your IdP (such as Okta). For authorization, you should be able to implement binary control that says who can access what data. And for auditing, you want to log as much as you can afford to store, which ideally means logging everything.
Consistency
We want to have the same security controls across the tech stack, irrespective of what type of database backend is being used. We want to make sure if there’s a field containing PII, we have a simple way to say ‘hey, anyone who is a data analyst cannot access social security numbers.’
Cyral gives you the ability to have consistent security controls across different databases. This includes both cloud-based and on-premises databases. So, whether you’re running Oracle or MS-SQL Server on-prem or Snowflake in the cloud, you have the same consistent security controls. You no longer need to think or do something different when running databases on-premises compared to running databases on AWS or on Google Cloud. In addition, Cyral gives you the exact same set of consistent access controls, access policies, and logging.
Scale
An increasing number of workloads and data are moving to the cloud. In addition, companies enable a growing number of employees to set up and use new databases on clouds such as AWS, Azure, Google Cloud, and others. As all of that happens, we must ensure that this increased move to the cloud is made in a default, secure manner.
Ideally, you want to implement guardrails within your company so that anyone who spins up a database – whether it’s next week, next month, or next year – will be protected by default. This means being consistent with the policies you’ve already implemented for your existing databases. It means to have consistent authentication, so your employees will manage users to the new database separately from your main IdP, or with a separate tool compared to how it’s done in the organization for other databases. It also means that if that newly created database is ever the subject of data leakage or a data security breach, it has the same consistent logging and auditing as our existing databases, enabling us to respond effectively to that data leakage.

Get Started with a
Free Trial
Get started in minutes: Explore how Cyral can protect your Data Mesh with our free trial. You can also contact us to schedule a live demo for a custom production security definition. Discover data privacy in production today.