
Do you use IAM to grant role-based access to RDS? Do you believe this grants you visibility into who’s running what queries in your database? Spoiler alert – you probably don’t have the visibility you think you do. Read on for the technical reasons behind this surprising fact.
A Computerized Whodunit
Before we dive in directly, let’s make sure we have a shared understanding of attribution and identity. What, exactly, is the concept of attribution in computer security?
Suppose you work at the FBI in its computer security division. Uh oh, somebody has broken into the mainframe! And now it’s your job to solve who broke in.
You walk over to your corrupted computer and type, “whoami” into the terminal. This reveals (gasp) the hacker’s username! But hm, lots of people pick their own usernames, and this hacker surely wouldn’t have picked a very revealing one.
You decide to gain the hacker’s IP address through logs. But wait, that’s not very helpful because anyone in a blackout zone who has used Tor to watch Sunday football knows it’s trivial to assume a geographically different IP address than your own.
But somehow you do identify the IP address, and even the computer’s physical address! You rush over to the house where the computer is, and find 5 people there. Now you have a new problem – who was at the keyboard when the FBI computer was compromised?
Luckily, someone at the house confesses – “It was me, you scoundrel, I broke into the FBI mainframe!” cries the hacker. The attack is their fault, right? But wait, as they speak to you it turns out that they were paid to attack you, and they don’t know by whom.
Who is responsible for this attack? To whom should it be attributed? Should the attack be attributed to the hacker’s username? To the IP address that made the call? To all 5 people at the house with the origin computer? To the hacker? To the foreign government paying the hacker?
Attribution is a complex problem not to be minimized. When protecting RDS instances, or any other type of database, we need to preserve the ability to attribute a query to a human. Luckily, we have identity for that.
How Do You Identify?
The concept of identity in computers is used to solve the problem of attribution. At your company, you probably take some or all of the following steps when someone is hired:
- Verify their identity through proof of right to work in the United States (if you happen to be in the US like me)
- Perform a background check
- Provide an email address or username for them to log into their new computer
My point is, you know, without a doubt, who is at the keyboard when they’re at their computer. You have taken pains to know who they are. If you’re using AWS, then through single sign-on you can extend this knowledge right into AWS by tying a user’s IAM account to their company account.
Bringing Identity to RDS
If you read my post about A Brief History of Database Security, you know that databases have been around for quite a long time and rely heavily upon password-based authentication. And RDS is nothing special – it’s just some database hosted by Amazon.
How will you grant access to 10, 50, or 100 users at your company? How will you grant access to applications like 10 web workers running simultaneously?
Option 1: Share Usernames and Passwords Across Groups
The very easiest thing to do is to create one username and password for each group to share inside a database. In this approach, all web workers might share the “web-worker” username and the password of “pa55w0rd”. Or, for employees, Alice and Bob might share a “data-science” username across the whole team.
The issue in this case is obvious. Not only do we not know who’s running which query in the database, but it might not even be the data science team. If the credentials are in an S3 bucket, it could be anybody who has seen the credentials. An unintended developer named Ellen with S3 bucket access could use them.
Option 2: Use Role-Based IAM Access
Consider the following architecture:
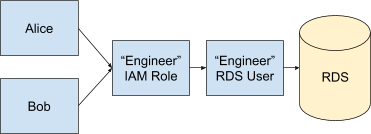
In this diagram, Alice and Bob both use AWS’ “Assume Role” functionality to become the role of an Engineer. That Engineer maps to one database user account called “Engineer”, and is then used in RDS to perform actions.
But what exactly does a log line look like? Here’s an example:
2020-11-16 16:45:14 UTC:[local]:engineer@postgres:[8839]:LOG: statement: SELECT d.datname as "Name",
pg_catalog.pg_get_userbyid(d.datdba) as "Owner",
pg_catalog.pg_encoding_to_char(d.encoding) as "Encoding",
d.datcollate as "Collate",
d.datctype as "Ctype",
pg_catalog.array_to_string(d.datacl, E'\n') AS "Access privileges"
FROM pg_catalog.pg_database d
ORDER BY 1;If Alice and Bob were both in RDS under the same role at the same time, who ran this query? There’s no way to tell.
This approach is nearly identical to approach 1. The only difference is that when Alice or Bob assume the role of Engineer, they must prove who they are.
In this approach, we still don’t have the ability to perform attribution. What we’ve gained is that Ellen can no longer get in. Or, in other words, username and password leaks don’t grant access to unintended third parties.
Option 3: Every IAM User Gets One Database User
This option gives fantastic insight into who is doing what query inside of RDS. However, AWS doesn’t create and delete IAM users for you inside your RDS instance as they come and go – you must do that.
If you’re a small organization, this may be an option. But it gains in difficulty as organizational complexity increases. Also, if you have applications like web workers accessing your database, will you have a separate user for each worker?
It gets difficult to avoid username-sharing and password-sharing very quickly. And because of that difficulty, in practice, most folks move very quickly to option 1 or 2.
Casting a Wider Net
None of the three options above provide an approach that is both easy and that provides attribution. Let’s look at options beyond what RDS offers out-of-the-box.
HashiCorp Vault
The Database Secrets Engine in Vault provides on-demand, short-lived database usernames and passwords.
For users, they can use any of Vault’s supported authentication methods to gain their short-lived usernames and passwords.
For applications, they can use Vault’s IAM auth method to gain a username and password.
Vault is available for free; however, you must be prepared to host it. You also will need to adjust code to take advantage of dynamic passwords, potentially self-run an auth agent, and teach your humans how to gain passwords from it.
All in all, it’s possible, though it does take some investment of resources.
Cyral
Cyral abstracts usernames and passwords away from users and applications, and perpetuates identity through all steps in the database use path.
For users, they can be assigned to roles with appropriate access levels. They can then leverage single sign-on to gain RDS access where their identity is propagated through every action they take.
For applications, an invisible sidecar preserves each instance’s identity while granting attributable access to RDS.
Cyral is objectively very quick to deploy, and requires no code change. Another advantage to this is the solution scales to pretty much any popular data service, beyond just RDS, so you don’t have to build a solution each time you evolve your architecture.
Wrapping Up
Does it surprise you that using IAM-based authentication to RDS does not provide the ability to attribute actions to an identity?
All in all, it’s very cool that AWS offers IAM-based authentication to RDS. It adds improved security over pure password-based authentication. I would recommend it anytime over straight-out username sharing approaches. However, to gain attribution, different approaches must be taken and a wider net must be cast.
Attribution not only enables us to track what happened in the past, but it provides a basis upon which we can perform anomaly detection to detect attacks in progress. In an upcoming post, we’ll dig into what that sort of data science looks like. Stay tuned!
