
Log management is a common problem in microservice architectures. One of the simplest and most common approaches for microservices to emit logs is to simply output them to the services’ standard streams (stdout/stderr), which is usually processed by the container runtime’s logging driver (if the service is running within a container). This usually results in the runtime writing these logs to files on disk somewhere, where they are later read and collected by external log collection agents. Unifying logs across multiple services for better understanding and analysis therefore often requires dedicated tooling (e.g. Fluentd, Fluent Bit), and special techniques (buffering, filtering, routing, etc.) to ensure performance and efficiency. Microservice architectures are usually faced with the following problems regarding logging:
- Log Volume and Scalability: With numerous services generating logs, the sheer volume of log data can quickly become overwhelming, potentially leading to storage issues and/or performance bottlenecks.
- Performance Overhead: Introducing extensive logging can add performance overhead to microservices (e.g. disk I/O). This can impact the overall response times and scalability of the system.
- Lack of Contextual Information: In complex microservice ecosystems, understanding the context of a log message (e.g., which service, which request, which user) is vital for effective debugging and monitoring. Without proper contextual information, identifying the root cause of issues becomes challenging.
- Inconsistent Logging Formats: Microservices are often developed by different teams, and without standardized logging practices, the formats and structure of logs can vary widely. This inconsistency makes it harder to aggregate and analyze logs effectively.
At Cyral, our sidecar is composed of a set of microservices which communicate and coordinate with each other. A core feature of the sidecar is that it is responsible for generating data activity logs. At its most basic level, the sidecar sits between users/applications and their databases, and analyzes and logs all database activity. These data activity logs are then often further distributed to various log management platforms (ELK, Splunk, etc.) by the sidecar itself, where they can be analyzed by administrators to detect things like data exfiltration, unauthorized access, or even just stored for future auditing.
Sidecar services all emit logs to their standard streams, in potentially different formats. They all emit basic diagnostic logs to stderr, and may also generate data activity logs to stdout. The sidecar also contains an embedded Fluent Bit engine, which is responsible for identifying and aggregating logs for each service, providing uniformity and context to the logs. Finally, logs may be output to various logging platforms (if configured) by Fluent Bit.

Because the sidecar often sits within the critical data path, its performance is extremely important. While the embedded Fluent Bit solves the issues of aggregation and provides context and consistency to logs, performance and scalability remain concerns. The sidecar uses many different techniques such as buffering, asynchronous execution, and non-blocking I/O to keep its performance impact minimal, however, in cases where applications are executing thousands (or more) of transactions per second, logging can become a non-trivial source of overhead. Ultimately, the sidecar must be able to aggregate and deliver logs while avoiding any performance bottlenecks.
In older sidecar iterations, the sidecar used the common approach to logging mentioned earlier: each microservice would emit logs to their standard streams, which would be handled by the container runtime and written to files on disk, and finally these files would be read and processed by Fluent Bit. However, naturally it resulted in disk I/O, and during load testing, we observed that this architecture could impact performance in very high throughput scenarios. Additionally, it might lead to a high monetary cost for users who need to simply provision hardware with enough IOPS to handle the load.

The sidecar is designed to handle database workloads at scale with minimal overhead, so we quickly realized this was unacceptable, and set out to solve the problem of efficient log management within the sidecar.
Initially we toyed with the idea of introducing a logging library to our services which would log directly to Fluent, using its Forward protocol, over a unix domain socket. This would solve the problem of disk I/O, but was a bit too inflexible for our needs, since not all sidecar services may be able to utilize such a library (e.g. if they were written in a different language).

We then had the idea of using named pipes (FIFOs) to funnel logs into Fluent Bit to avoid hitting the disk altogether. Microservices would have their output redirected to a set of named pipes (specific to each service), and the pipes would be read by Fluent Bit. Again, this solved the disk I/O problem – logs were now contained 100% within memory as they moved from microservice, to Fluent Bit, to some external logging platform. And it seemed to solve the problem of compatibility as well, since redirecting standard output streams to a named pipe of any process is easily doable from the shell.
Unfortunately, we ran into a few problems with this architecture:
- The Fluent Bit engine has no way to natively read from named pipes. We would need to either modify it ourselves to support reading from pipes, or use some intermediary process to read from the pipes and forward the contents to Fluent Bit using some other mechanism.
- While named pipes support buffering and non-blocking I/O, applications would need to be modified to handle write errors when the pipe buffer was full, or there was no reader available on the other end. This could lead to services getting blocked or failing unexpectedly.
- Modifying the pipe buffer size proved to be inflexible. Pipe buffer sizes are set as a number of bytes, however we wanted to buffer logs based on the number of log lines instead. Also, the max pipe buffer size is a kernel setting, which defaults to 16 pages (65536 bytes in a system with a page size of 4096 bytes). We wanted the ability to buffer larger amounts of data than that, however we were not comfortable with needing to change the pipe buffer size for the entire host just for the benefit of the sidecar.

Ultimately, our solution was somewhat of a combination of both the library and pipe approaches. Instead of using named pipes, we would use unnamed pipes (taking some inspiration from the design of Docker’s logging drivers). We built a small wrapper process (called log2fluent) which we would use to launch each microservice. The wrapper would first create two unnamed pipes (one for stdout and one for stderr), and then fork-exec the service as a child process and redirect its standard streams to the pipes. The wrapper would then read each output log line from the pipes, and send them to Fluent using the Forward protocol over a unix domain socket. Logs would be identified with the service name and stream from which the originated from.
To handle back pressure scenarios, buffering would be built into the wrapper, with configuration options such as buffer size, and a configurable strategy in the face of back pressure (drop messages, re-queue, etc.). By default, we opted to drop log messages when the buffer was full.
We used IBM’s fluent-foward-go library, which is a lightweight and performant implementation of the Fluent Forward specification.
The Fluent Bit engine would listen on two sockets, one corresponding to each stream (stdout and stderr), and the wrapper would forward the logs to the corresponding socket. Fluent would then tag the log messages appropriately by stream, and process the logs as they arrived. Finally, it would forward them to any configured destinations (or just write them to stdout/stderr).
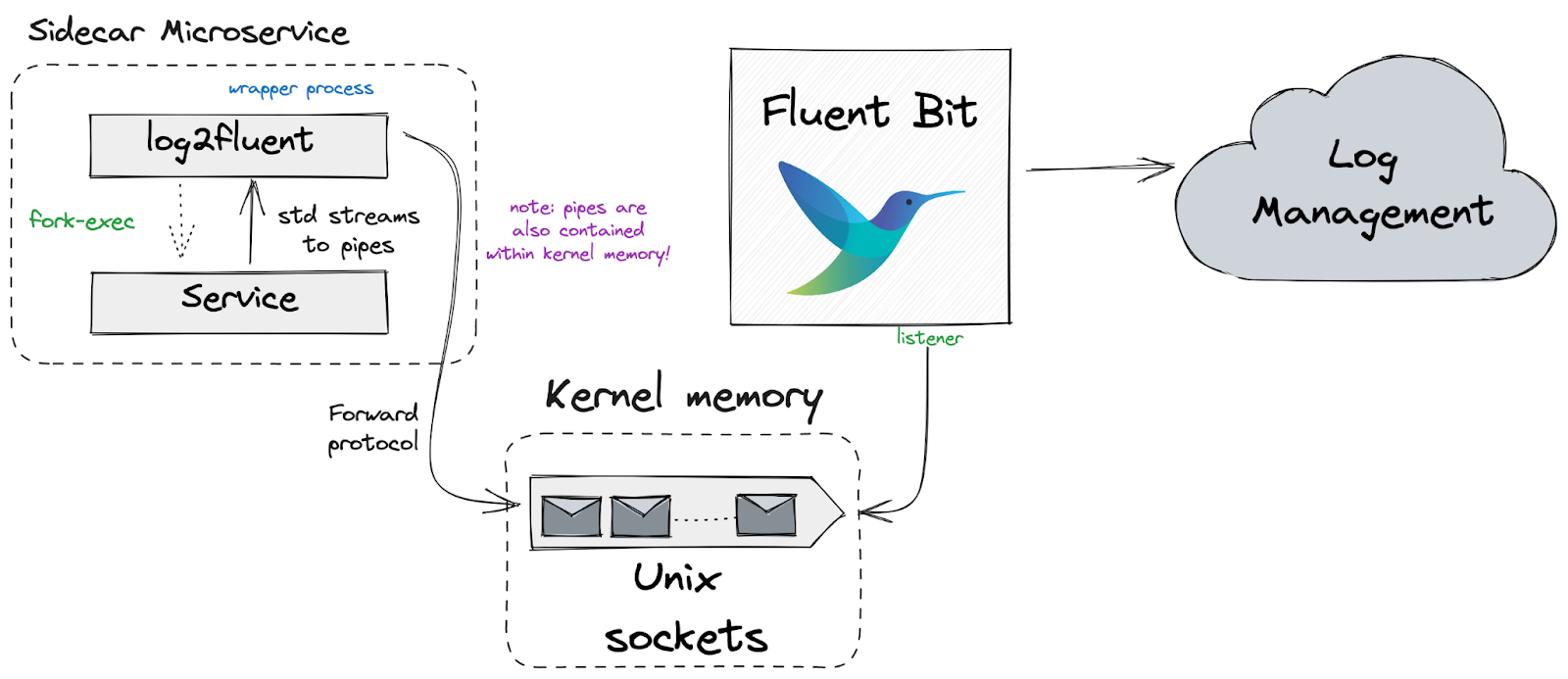
Ultimately, the solution accomplished the following:
- It kept log messages in memory and eliminated disk I/O by the sidecar.
- Logs could still be identified and contextualized per service.
- It allowed services to write logs without worrying about blocking, and the buffering parameters and back-pressure behavior was easily configurable.
- It worked for any application, written in any language.
- It was highly performant and added minimal overhead to the sidecar.
As stated earlier, the sidecar cannot compromise on performance, and must never become a performance bottleneck, yet it must also have the capability to aggregate and output potentially large volumes of log data across a mesh of microservices. By using unnamed pipes for interprocess communication between the log2fluent wrapper and the microservices, as well as Unix sockets as the channel to transmit logs, we were left with a lightweight and flexible architecture for managing log data. Ultimately, performance testing validated our solution as well, and we felt that we accomplished our goals.
