
There are few things as buzzy in the industry right now as the modern data stack. With tools like Presto, Airflow, dbt, etc soaring in popularity and platforms like Databricks, Lake Formation, Snowflake, etc, becoming all things to all people, and services like Kafka, FiveTran, Census, etc becoming hyper specialized, it is impossible for non-experts to stay on top of the terms, technologies and their classification.
One of the core challenges we have seen is by the time the security team has developed a clear plan to get a handle on security of a data engineering tool, it often gets augmented or even replaced by a new one! With a lack of consistent vernacular on how these tools are used, what they do, and how they differ from one another, securing the data stack becomes a moving target for security, data and devops teams alike.
In this blog post we present a model that we share with our customers to help them devise a security plan that is extensible and operationable, and not one that keeps changing with the constant evolution of their organization’s data stack.
A data engineer’s view of the modern data stack
There are several great resources that provide an overview of the modern data stack – but the one we liked the most was written by the team at a16z and is available here.
This post does a terrific job of explaining how the data infrastructure has evolved over the years to handle business intelligence needs, from vanilla BI tool reporting to supporting AI/ML and complex data modeling. At its core, it provides the following reference architecture for the modern data stack:
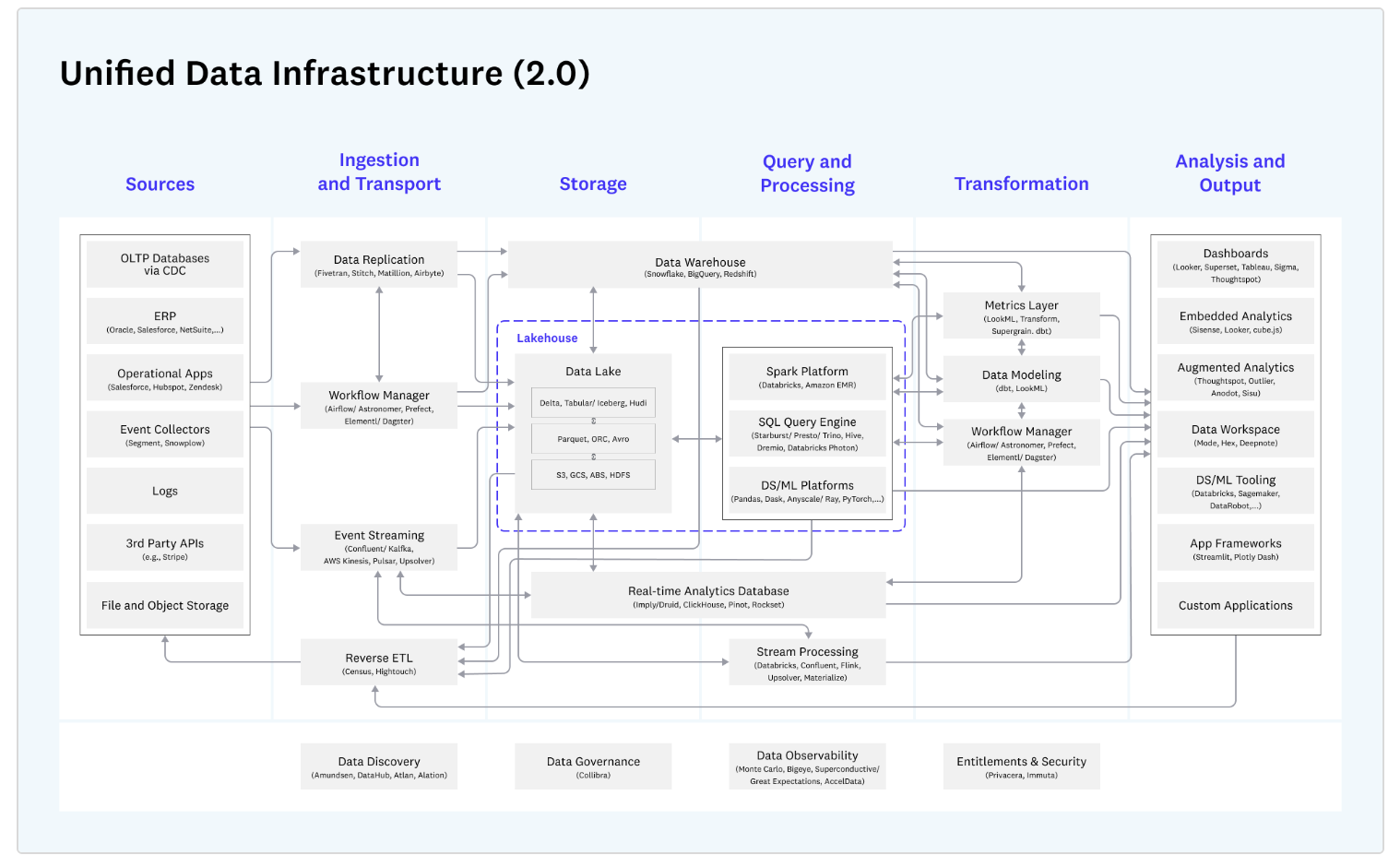
Much like the iconic New Yorker’s view of the world from 9th Avenue, this depicts how data engineers and their teams comprehend the data stack.
Unfortunately, security teams have their own messy landscape to deal with (example here) made with terms like SASE, Zero Trust, DLP, IGA, etc which take a career’s worth of investment to internalize. It is infeasible for most teams to reconcile these two convoluted and highly dynamic frameworks with each other, and stay on top of emerging tool choices.
A security engineer’s view of the data stack
Despite the sophistication of use cases the various data tools enable for data teams, we can break these down into three broad categories that security teams are well versed with –
- Data at Rest – these are database, and database-like repositories (eg S3) where data is stored in some format and used for some purpose
- Data in Motion – these are pipelines and various connectors (eg Airflow) that enable different kinds of automated processing on the data and move them from one data repository to another
- Data in Use – these are typically some UI-based client which enable different people in the organization to visualize and experiment with the data
If we trace the data flow, we can come up with the following representation of the data stack
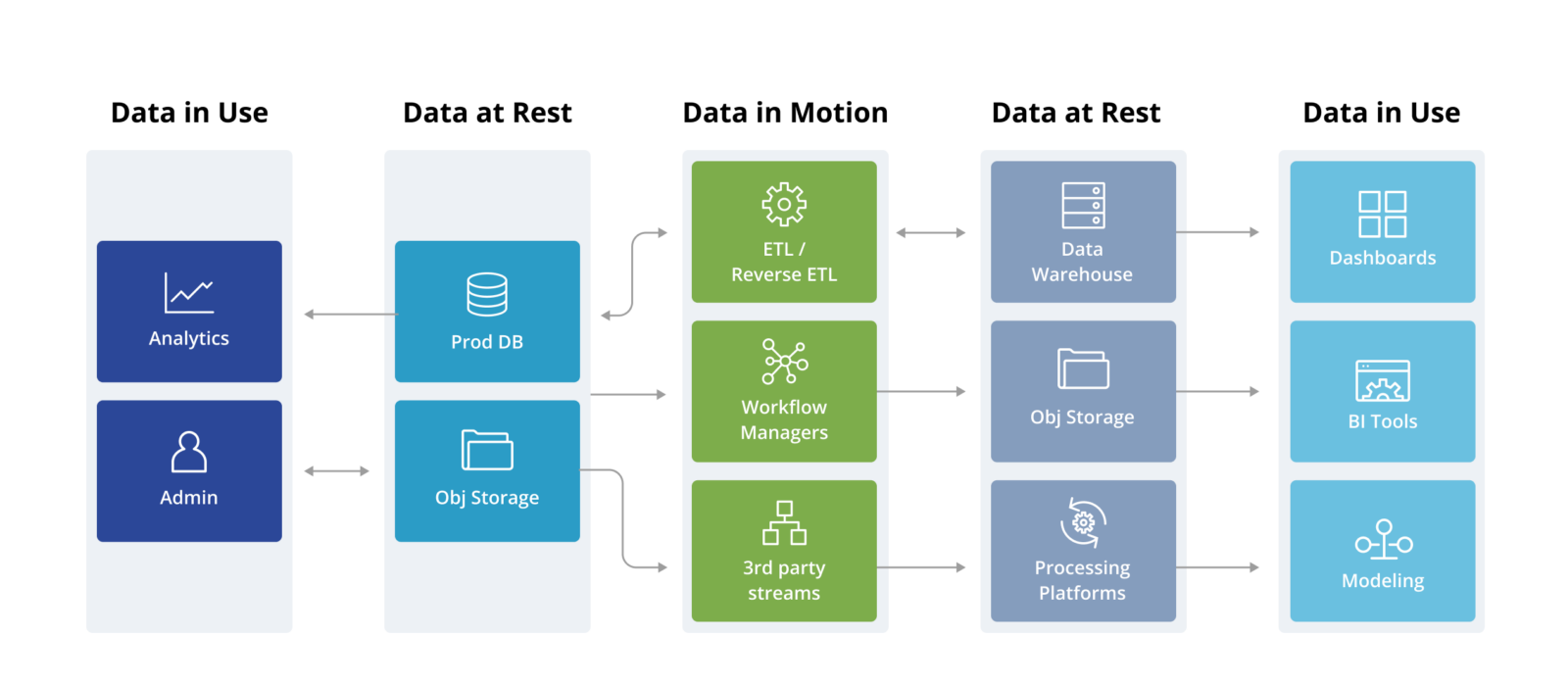
Now, security teams are able to apply their familiar security policies of encryption, tokenization, etc on the above data, and implement controls for the following:
- Centralized identity-based authentication to data at rest
- Ensure correct privileges for all data in use and in motion
- Consistent real-time visibility and monitoring
- Unified policies on all workloads (read, write, update)
Parting thoughts: A quick checklist for your data team colleagues
Best outcomes happen only when everyone works together. You can share this checklist with your data team to help them ensure the right security configuration of their data stack, and pull you in only when they get stuck!
- Can this repository be accessed over a network?
- Ensure that encryption in transit is enabled by default
- Limit access to privileged accounts from known network locations only
- Does this tool or repository require users to log into it?
- SSO should be enabled for all users
- Privileged operations should be allowed only with just-in-time access
- Does this data repository have confidential or PII data in it?
- That data should only be visible to specialized accounts and masked for all other accounts
- Only named users should be able to log into above specialized accounts with their SSO credentials
- Ask if you can have query rate limiting enabled for all users
- Is the data in this repository subject to any regulatory requirements?
- Enable access and query logging at the field-level
- Ensure MFA is enabled for all connections into the repository
- Implement field-level access controls
- Does a tool transfer data across multiple repositories, and one has sensitive data in it?
- Ensure there are inline-controls that mask or redact data as it flows out of that data repository
- Implement service account monitoring for the tool against each repository
Protecting your data from breaches is hard already, and the ongoing flux in the data stack makes it even more difficult. Hopefully this above checklist can provide a simple framework for teams to collaborate on making it easier.
