
Overview
In this blog post, we are going to describe how flow logs may be analyzed using Dremio to look for signs of intrusion and possible signs of data exfiltration from an AWS RDS instance.
Flow logs capture essential information regarding network connections as traffic passes a network interface. Examples of the kind of data collected include the source and destination IP addresses, ports, number of packets / bytes, as well as start and end times of the packet transfers. Because of the structured nature of the logs, they may be imported for querying and analysis in modern data processing platforms such as Dremio, AWS Athena and Google BigQuery.
On AWS, flow logs can be enabled at the VPC level. The captured logs can be configured to be sent to an S3 bucket at regular intervals of up to 10 minutes each.
Setup
RDS instance
- Set up as a honeypot and publicly accessible
- Internally accessed by a few of Cyral’s developers. These connections are typically short lived (in the order of a few minutes) and used to test authentication mechanisms
- Contains synthetically generated data comprising fake Social Security Numbers and Credit Card Numbers
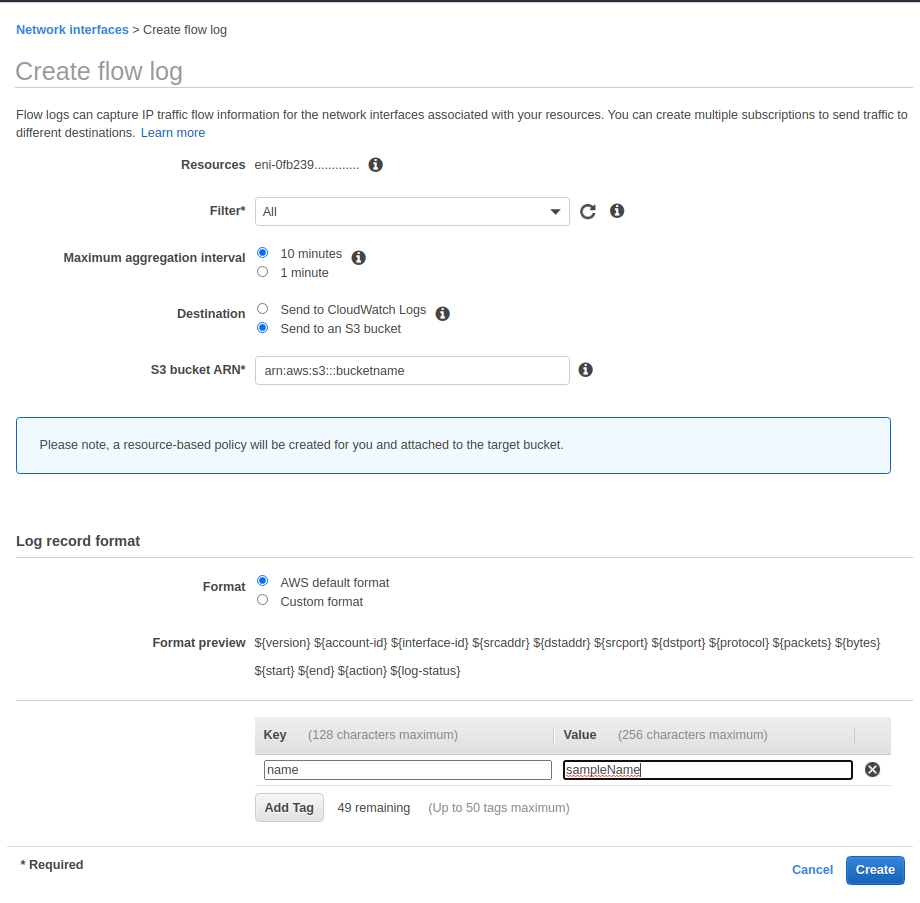
Enabling flow logs
- Flow logs were enabled as described in the AWS documentation
- Specifically, the Filter attribute was set to All to log all traffic, Maximum aggregation interval was set to 10 minutes, and the logs destination was chosen to be an S3 bucket
Connecting Dremio to S3
Flow logs data in the S3 bucket was organized into virtual datasets in Dremio as follows:
- A Dremio Space was created to store the virtual datasets
- The private S3 bucket containing the flow logs was added as a data source by providing the Access Key and the Secret Key
- Next, in order for Dremio to interpret the log data, the Field Delimiter was set to the space character (\u0020), the Line Delimiter was set to the Unix line feed (\n)
- Overall, three virtual datasets were created. One for the raw S3 bucket data, another for to aggregate the results over a day, and the third to aggregate the results over a week.
Flow Logs Analysis
We collected 7 days’ worth of flow logs from the RDS instance. Each file in the S3 bucket corresponds to a 10 minute interval of flow logs, thus we ended up with over 1000 files in the S3 bucket. For our analysis, we selected one of the 10 minute intervals for which we knew that the traffic from our internal developers would be very little.
Step 1
We started off by determining the number of unique IP addresses from where the connections originated.
Query:
SELECT distinct(srcaddr)
FROM AWSFlowLogs.day01."0200"Results:
[('172.30.0.189', ), ('201.48.16.81', ), ('172.30.2.136', ), ('172.30.2.121', ), ('172.30.4.101', )]The IP 201.48.16.81 turned out to be unknown. Geolocating the IP address told us it was from somewhere in Brazil. The specific location was unexpected given our developers didn’t own this IP address.
Step 2
Next, we wanted to check how long the particular connection from the unknown IP address was alive in this particular interval since connections to the RDS instance are typically short lived.
Query:
SELECT TO_TIMESTAMP(x.start_time), TO_TIMESTAMP(x.end_time)
FROM (SELECT MIN("start") AS start_time,
MAX("end") AS end_time
FROM AWSFlowLogs.day01."0200"
WHERE srcaddr = '201.48.16.81' ) xResults:
[(’2020-09-16 02:05:03’, ’2020-09-16 02:15:02’)]Turned out the connection has been alive for the entire 10 minutes of the flow logs capture interval.
Step 3
We then ran a modified version of the preceding query over several flow log intervals to determine when the connection from the IP address first originated, and when it finally got disconnected.
Query:
SELECT x.start_time, x.end_time, x.end_time - x.start_time
FROM (SELECT TO_TIMESTAMP(MIN("start")) AS start_time,
TO_TIMESTAMP(MAX("end")) AS end_time
FROM AWSFlowLogs.day01.aggregated
WHERE srcaddr = '201.48.16.81' ) xResults:
[(‘2020-09-16 02:01:27’, ‘2020-09-16 02:25:13’)]Connection from the IP address was alive for a total of 24 minutes.
Step 4
Curious to examine the data transfer patterns, we drilled down into how many bytes of data were read by this connection from the RDS instance over the entire 24 minutes that it was alive.
Query:
SELECT bytes, "start", "end"
FROM AWSFlowLogs.day01.aggregated
WHERE dstaddr = '201.48.16.81'
AND "start" >= 1600221687
AND "end" <= 1600223113
ORDER BY "start" ASC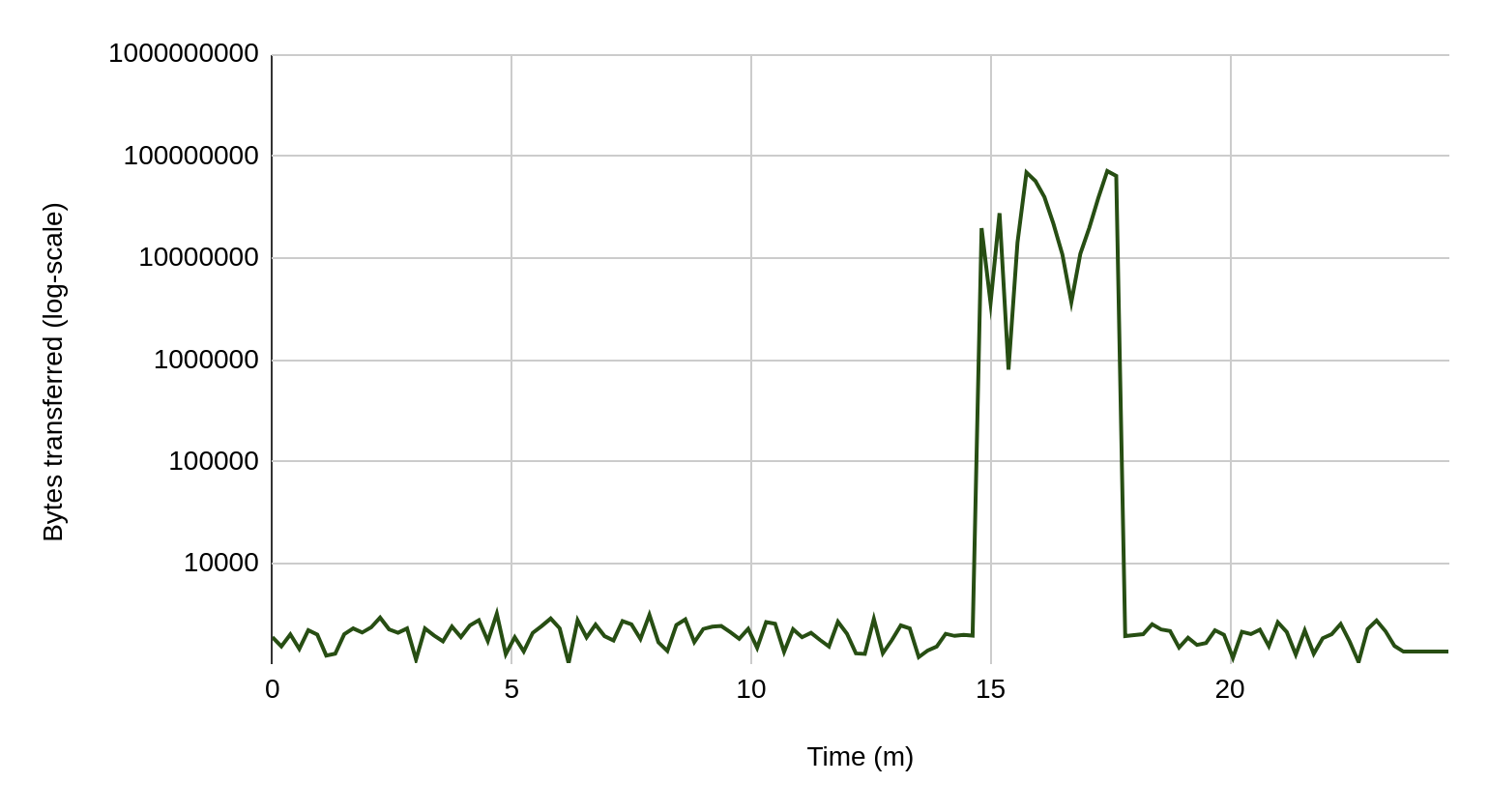
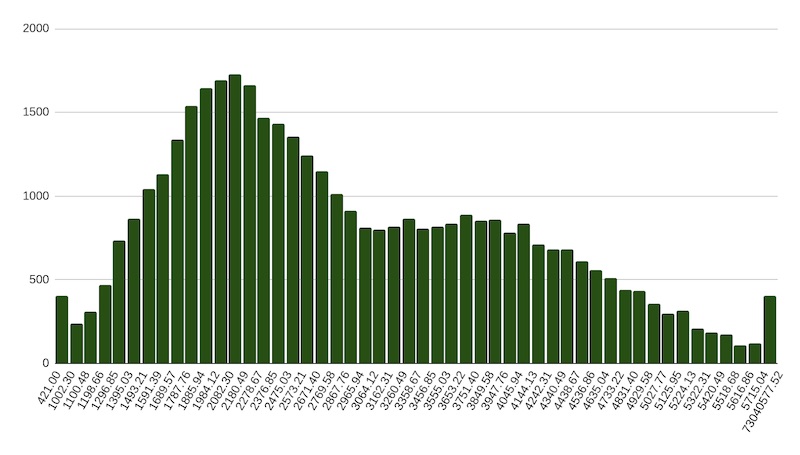
For most of the 24 minutes, there wasn’t much transfer of data from the RDS instance. For 3 minutes, however, there’s a spike resulting in almost 1GB of data leaving the RDS instance. This likely means the initial time was spent doing reconnaissance – attempting to log in to the database, poking around the various schemas and tables looking for where the PII is. Once it was found, data in the relevant tables was exfiltrated all at once. The responses from the database were mostly ranging from 1200 to 5700 bytes, with most traffic transferring around 2100 bytes. However, we see at the end the usual traffic leading to transfers up to 73 MB, each.
Step 5
As a final step, to ensure that the observed spike is in fact an outlier, we computed the mean and standard deviation for the bytes transferred attribute over the 7 day period.
Query:
SELECT x.mean, x.dev, ( x.mean + 3 * x.dev )
FROM (SELECT Avg(bytes) AS mean,
Stddev(bytes) AS dev
FROM awsflowlogs.week
WHERE srcport = 3306) x Results:
[(5614.02, 712.74, 7752.22)]And we used the distance of 3 sigma from the mean to filter the average of bytes sent to the unknown IP, showing that the spike, in fact, corresponded to an outlier.
SELECT Avg(bytes)
FROM awsflowlogs.week
WHERE dstaddr = '201.48.16.81'
AND srcport = 3306
AND bytes > 7752 Results: 68041153.94 bytes or 68.04 MB
Conclusion
Using a versatile data processing platform such as Dremio, we were able to analyze AWS VPC flow logs to identify and trace malicious data exfiltration activity. It’s important to note here that while useful for a preliminary security analysis of data transfer patterns, flow logs should not be the only source to rely on, and doing so will result in false positives. This is due to the absence of any database-specific semantic context at the level of network bytes. For example, it may not be clear whether the data being transferred is sensitive PII or just innocuous not warranting an alert. Flow logs also do not reveal the identity of an attacker besides their IP address. For these reasons, flow logs analysis should be used with caution for any serious forensics activity. In a subsequent blog post, we will describe how data exfiltration attempts could be identified and traced with certainty along with enriched information such as the identity of the attacker and the specific PII that was exfiltrated.
