
At Cyral, we run our services across various clouds, and with the increase in number of customers and use cases, we’ve experienced the pain points of using various tools to manage different parts of our heterogeneous infrastructure. We recently decided to mitigate some of them with Google’s brand new config-connector, and are very excited at what it can do for us.
Multi-cloud and the complexity of orchestration
Most folks who use the cloud are familiar with at least one cloud orchestration tool. From cloud specific tools like Cloudformation, Microsoft Azure Deployment and Cloud Deployment Manager to cloud-agnostic offerings like Terraform; there are options to meet almost any requirement. Each of these tools has its own strengths [1] and nuances.
One of the reasons for the heterogeneity in these tools is that nearly all of them treat cloud resources as concrete offerings from different cloud providers rather than treating them as abstract concepts of distributed computing. For example, a bucket is referred to as either an S3 object for AWS, gs object for GCP when buckets are created with terraform or similar tools.
Kubernetes to the rescue
Kubernetes entered the zoo of orchestration tools with the promise of abstracting the various cloud services into higher level concepts that are easy to understand and manage. So instead of assembling a bunch of concrete resources and then orchestrating them, one could define the desired state at a higher level and let Kubernetes handle the provisioning, monitoring and destruction of these resources. For example, a declaration of a Kubernetes service’s type as “LoadBalancer” [2] would automatically create the cloud’s native load balancer and point it to your service’s instance.
This is incredibly powerful since you can quickly build and tear down logical pieces of your infrastructure without having to worry about the details of the cloud provider’s implementation of those pieces – this would work well across cloud environments. For example load balancers would be supported with ELB in AWS and Cloud Load Balancer in GCP. Similarly, concepts like block storage, ingresses etc would be mapped onto their respective offerings for different cloud providers. This power was however limited to Kubernetes resource types [3] like pods, volumes, services etc and does not handle other cloud resources like managed databases, IAM roles, lambda functions etc.
Multi step workflow with Kubernetes
Teams using Kubernetes would usually have to undertake a multi-step approach to bring up all the pieces required by any modern stack. The process begins with using an orchestration tool like terraform to bring up the pieces which are not native to Kubernetes (for example a database or certificates). The endpoints/URLs of these resources would then be injected as a dependency in the Kubernetes deployment(s) and bring up the rest of the stack via Kubernetes.
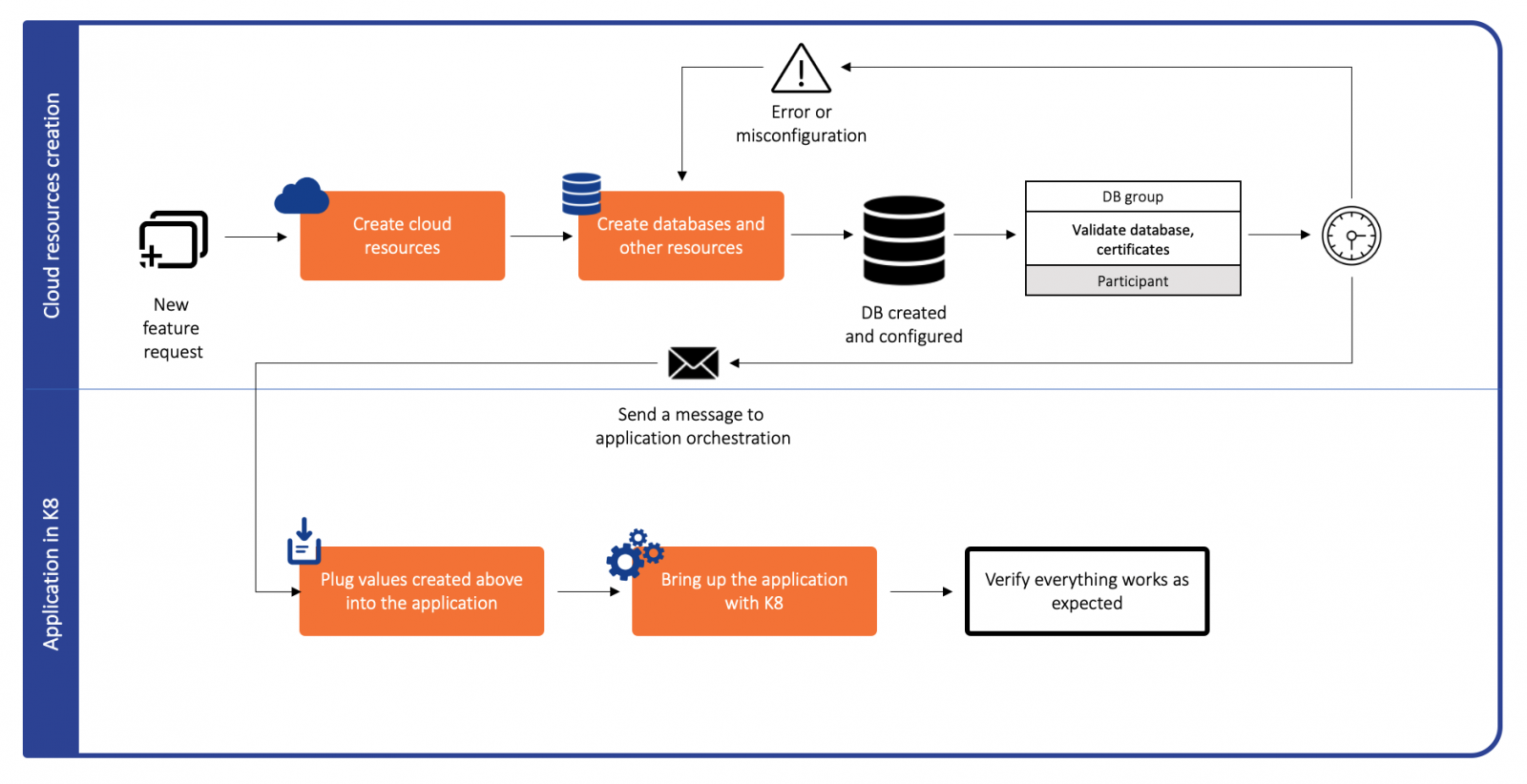
This model suffers from two major issues:
- Teams need to synchronize to manage different tools and timelines for different pieces of the software stack.
- Non-native Kubernetes resources (like the database in the example above) need to be monitored and remedied via a different flow depending on the tool used to bring them up.
The multi-step flow hence increases complexity and cognitive load on developers and maintainers.
Config-connector as the glue
Google Cloud Platform recently released the config-connector for general availability [4]. Config connector facilitates the declaration of resources which were not Kubernetes native as pseudo native Kubernetes resources. With this glue, teams can declare and maintain cloud resources with a single orchestration tool like Kubernetes.
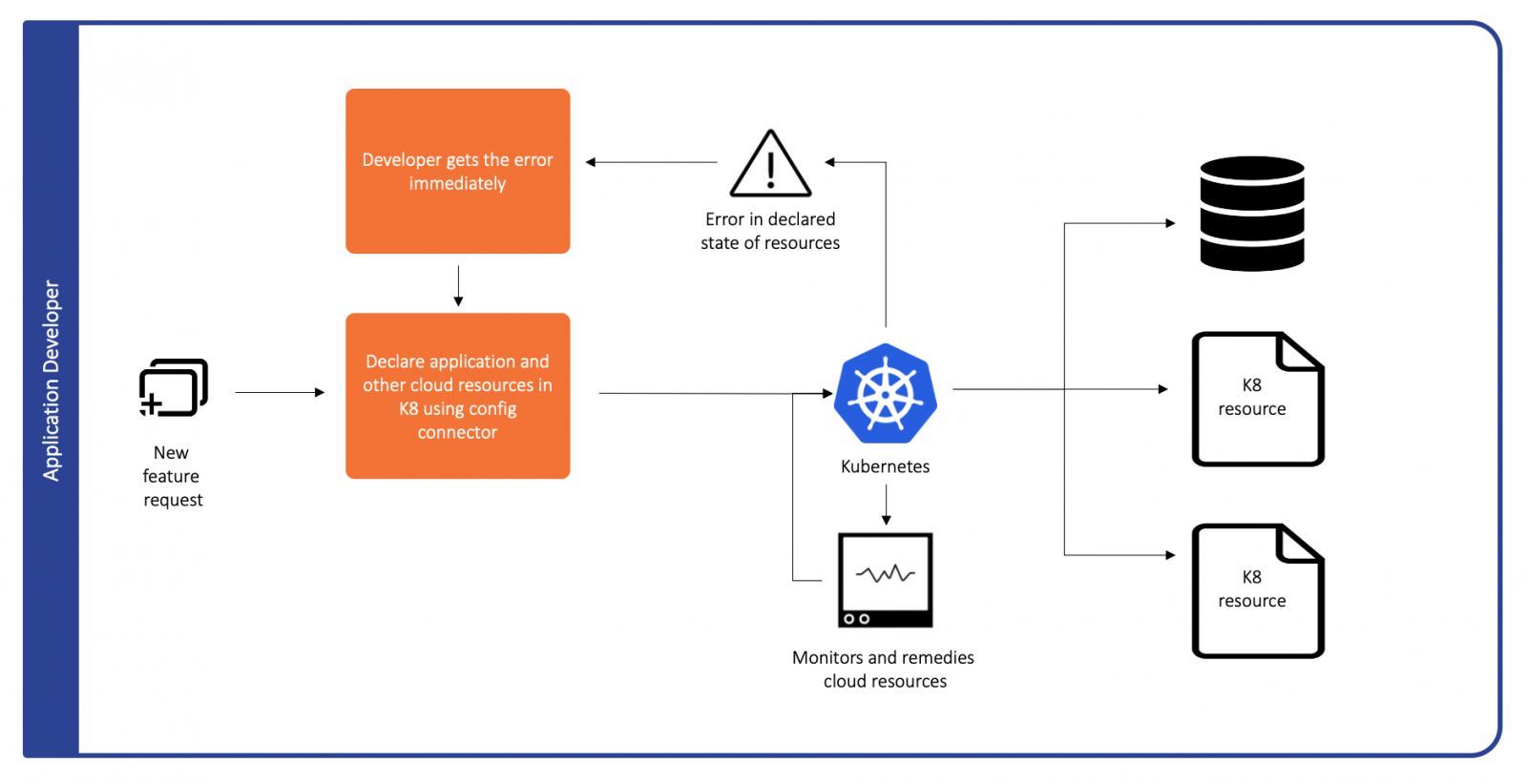
In the example above, the database and certificates can now be brought up and down along with the rest of the stack using Kubernetes. These resources can now be monitored as well via Kubernetes with eventual consistency guarantees. If you use RBAC for access control to your Kubernetes resources, it can now be extended to previously non-Kubernetes resources as well.
Moving infrastructure orchestration to a single tool would reduce the complexity of processes required to manage those resources and reduce the cognitive load for developers creating and maintaining those resources. A potential downside of config-connector, however, is vendor lock-in since it’s available only for GCP.
Why this is a potential gamechanger
With this addition Kubernetes now has a powerful new paradigm of orchestrating and managing our entire cloud deployment on GCP. Kubernetes excelled at scaling at monitoring modern cloud concepts like elastic compute and storage and they seem to be extending these strengths to resources outside of that ecosystem.
We hope to share our experience with this migration and subsequently manage our real workload of services in this new framework. If you yourself have stories you’d like to share, please reach out to us!
References
- [1] The Best Tools for Cloud Infrastructure Automation
- [2] Kubernetes: Create an External Load Balancer
- [3] Kubernetes: Overview of kubectl
- [4] Config Connector bridges Kubernetes, GCP resources
Image by John Hurley via the OpenIDEO Cybersecurity Visuals Challenge under a Creative Commons Attribution 4.0 International License
